
Scenario: When Plain SQL Isn’t Enough
As a data analyst, you face these questions daily:
- “Who are the TOP 3 performers in each sales region?”
- “How did this month’s sales change compared to last month?”
- “What are the highest and lowest salaries in each department?”
- “Can we split customers into 4 tiers by revenue?”
You could do all of this with GROUP BY + subqueries, but your SQL would get messy fast. Window functions were built exactly for these use cases — they let you compute across rows without collapsing the result set.
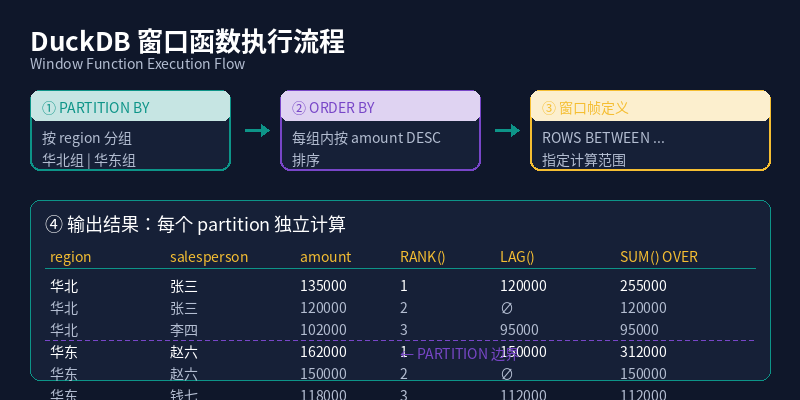
Figure: Window function execution flow — PARTITION BY groups data, ORDER BY sorts within groups, then the window frame is applied
Runtime: DuckDB CLI v1.5.2, zero Python dependencies required.
Sample Data Setup
Run the following SQL directly in DuckDB CLI:
-- Sales performance table
CREATE TABLE sales AS SELECT * FROM (
VALUES
('North', 'Alice', '2026-01', 120000),
('North', 'Bob', '2026-01', 95000),
('North', 'Carol', '2026-01', 88000),
('North', 'Alice', '2026-02', 135000),
('North', 'Bob', '2026-02', 102000),
('North', 'Carol', '2026-02', 91000),
('East', 'Dave', '2026-01', 150000),
('East', 'Eve', '2026-01', 112000),
('East', 'Frank', '2026-01', 98000),
('East', 'Dave', '2026-02', 162000),
('East', 'Eve', '2026-02', 118000),
('East', 'Frank', '2026-02', 105000)
) AS t(region, salesperson, month, amount);
-- Employee salary table
CREATE TABLE employees AS SELECT * FROM (
VALUES
('Engineering', 'Alice', 'Senior Engineer', 28000),
('Engineering', 'Bob', 'Architect', 35000),
('Engineering', 'Carol', 'Junior Engineer', 15000),
('Marketing', 'Dave', 'Marketing Director', 32000),
('Marketing', 'Eve', 'Marketing Specialist', 18000),
('Marketing', 'Frank', 'Marketing Specialist', 16000),
('Finance', 'Grace', 'Finance Director', 30000),
('Finance', 'Heidi', 'Accountant', 20000),
('Finance', 'Ivan', 'Treasurer', 14000)
) AS t(dept, name, position, salary);
1. Ranking: RANK, DENSE_RANK, ROW_NUMBER
Problem: Top 3 salespeople in each region
SELECT
region,
salesperson,
month,
amount,
ROW_NUMBER() OVER (PARTITION BY region ORDER BY amount DESC) AS row_num,
RANK() OVER (PARTITION BY region ORDER BY amount DESC) AS rank,
DENSE_RANK() OVER (PARTITION BY region ORDER BY amount DESC) AS dense_rank
FROM sales;
Output:
┌────────┬────────────┬────────┬────────┬─────────┬──────┬────────────┐
│ region │ salesperson│ month │ amount │ row_num │ rank │ dense_rank │
├────────┼────────────┼────────┼────────┼─────────┼──────┼────────────┤
│ North │ Alice │ 2026-02│ 135000 │ 1 │ 1 │ 1 │
│ North │ Alice │ 2026-01│ 120000 │ 2 │ 2 │ 2 │
│ North │ Bob │ 2026-02│ 102000 │ 3 │ 3 │ 3 │
│ North │ Bob │ 2026-01│ 95000 │ 4 │ 4 │ 4 │
│ North │ Carol │ 2026-02│ 91000 │ 5 │ 5 │ 5 │
│ North │ Carol │ 2026-01│ 88000 │ 6 │ 6 │ 6 │
│ East │ Dave │ 2026-02│ 162000 │ 1 │ 1 │ 1 │
│ East │ Dave │ 2026-01│ 150000 │ 2 │ 2 │ 2 │
│ East │ Eve │ 2026-02│ 118000 │ 3 │ 3 │ 3 │
│ East │ Eve │ 2026-01│ 112000 │ 4 │ 4 │ 4 │
│ East │ Frank │ 2026-02│ 105000 │ 5 │ 5 │ 5 │
│ East │ Frank │ 2026-01│ 98000 │ 6 │ 6 │ 6 │
└────────┴────────────┴────────┴────────┴─────────┴──────┴────────────┘
Figure: RANK() window function execution result in DuckDB CLI
The Three Ranking Functions Compared
| Function | Behavior | Example (ties) |
|---|---|---|
ROW_NUMBER() | Sequential numbers, no ties | 1, 2, 3, 4 |
RANK() | Same rank for ties, skips next | 1, 1, 3, 4 |
DENSE_RANK() | Same rank for ties, no skip | 1, 1, 2, 3 |
Let’s see how they differ when there are duplicate values:
SELECT
dept,
name,
salary,
ROW_NUMBER() OVER (ORDER BY salary DESC) AS row_num,
RANK() OVER (ORDER BY salary DESC) AS rank,
DENSE_RANK() OVER (ORDER BY salary DESC) AS dense_rank
FROM employees;
Output:
┌─────────────┬───────┬────────┬─────────┬──────┬────────────┐
│ dept │ name │ salary │ row_num │ rank │ dense_rank │
├─────────────┼───────┼────────┼─────────┼──────┼────────────┤
│ Engineering │ Bob │ 35000 │ 1 │ 1 │ 1 │
│ Marketing │ Dave │ 32000 │ 2 │ 2 │ 2 │
│ Finance │ Grace │ 30000 │ 3 │ 3 │ 3 │
│ Engineering │ Alice │ 28000 │ 4 │ 4 │ 4 │
│ Finance │ Heidi │ 20000 │ 5 │ 5 │ 5 │
│ Marketing │ Eve │ 18000 │ 6 │ 6 │ 6 │
│ Marketing │ Frank │ 16000 │ 7 │ 7 │ 7 │
│ Engineering │ Carol │ 15000 │ 8 │ 8 │ 8 │
│ Finance │ Ivan │ 14000 │ 9 │ 9 │ 9 │
└─────────────┴───────┴────────┴─────────┴──────┴────────────┘
Pro tip: To get Top N per group, wrap in a subquery and filter:
SELECT * FROM ( SELECT *, RANK() OVER (PARTITION BY region ORDER BY amount DESC) AS r FROM sales ) WHERE r <= 3;
2. Month-over-Month Analysis: LAG and LEAD
Problem: How much did each salesperson’s revenue change month-over-month?
SELECT
region,
salesperson,
month,
amount,
LAG(amount) OVER (PARTITION BY salesperson ORDER BY month) AS prev_month,
amount - LAG(amount) OVER (PARTITION BY salesperson ORDER BY month) AS change,
ROUND((amount - LAG(amount) OVER (PARTITION BY salesperson ORDER BY month))
/ LAG(amount) OVER (PARTITION BY salesperson ORDER BY month) * 100, 1) AS change_pct
FROM sales
ORDER BY salesperson, month;
Output:
┌────────┬────────────┬────────┬────────┬───────────┬────────┬───────────┐
│ region │ salesperson│ month │ amount │ prev_month│ change │ change_pct│
├────────┼────────────┼────────┼────────┼───────────┼────────┼───────────┤
│ North │ Alice │ 2026-01│ 120000│ ∅ │ ∅ │ ∅ │
│ North │ Alice │ 2026-02│ 135000│ 120000 │ 15000 │ 12.5 │
│ North │ Bob │ 2026-01│ 95000 │ ∅ │ ∅ │ ∅ │
│ North │ Bob │ 2026-02│ 102000│ 95000 │ 7000 │ 7.4 │
│ North │ Carol │ 2026-01│ 88000 │ ∅ │ ∅ │ ∅ │
│ North │ Carol │ 2026-02│ 91000 │ 88000 │ 3000 │ 3.4 │
│ East │ Dave │ 2026-01│ 150000│ ∅ │ ∅ │ ∅ │
│ East │ Dave │ 2026-02│ 162000│ 150000 │ 12000 │ 8.0 │
│ East │ Eve │ 2026-01│ 112000│ ∅ │ ∅ │ ∅ │
│ East │ Eve │ 2026-02│ 118000│ 112000 │ 6000 │ 5.4 │
│ East │ Frank │ 2026-01│ 98000 │ ∅ │ ∅ │ ∅ │
│ East │ Frank │ 2026-02│ 105000│ 98000 │ 7000 │ 7.1 │
└────────┴────────────┴────────┴────────┴───────────┴────────┴───────────┘
Alice leads the North region with a 12.5% month-over-month increase, while Carol only grew 3.4% — worth investigating.
LEAD: Looking ahead
SELECT
salesperson,
month,
amount,
LEAD(amount) OVER (PARTITION BY salesperson ORDER BY month) AS next_month,
LEAD(amount, 2) OVER (PARTITION BY salesperson ORDER BY month) AS next_two_months
FROM sales
ORDER BY salesperson, month;
Pro tip:
LAG(col, n)looks back n rows,LEAD(col, n)looks forward n rows (default n=1). This is invaluable for period-over-period analysis and rolling comparisons.
3. Partition Extremes: FIRST_VALUE and LAST_VALUE
Problem: Who’s the highest and lowest paid in each department?
SELECT
dept,
name,
position,
salary,
FIRST_VALUE(name || ' (' || salary || ')') OVER (
PARTITION BY dept ORDER BY salary DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
) AS highest_paid,
LAST_VALUE(name || ' (' || salary || ')') OVER (
PARTITION BY dept ORDER BY salary DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
) AS lowest_paid,
MAX(salary) OVER (PARTITION BY dept) - salary AS gap_to_top
FROM employees
ORDER BY dept, salary DESC;
Output:
┌─────────────┬───────┬──────────────────────┬────────┬──────────────────┬──────────────────┬────────────┐
│ dept │ name │ position │ salary │ highest_paid │ lowest_paid │ gap_to_top │
├─────────────┼───────┼──────────────────────┼────────┼──────────────────┼──────────────────┼────────────┤
│ Engineering │ Bob │ Architect │ 35000 │ Bob (35000) │ Carol (15000) │ 0 │
│ Engineering │ Alice │ Senior Engineer │ 28000 │ Bob (35000) │ Carol (15000) │ 7000 │
│ Engineering │ Carol │ Junior Engineer │ 15000 │ Bob (35000) │ Carol (15000) │ 20000 │
│ Finance │ Grace │ Finance Director │ 30000 │ Grace (30000) │ Ivan (14000) │ 0 │
│ Finance │ Heidi │ Accountant │ 20000 │ Grace (30000) │ Ivan (14000) │ 10000 │
│ Finance │ Ivan │ Treasurer │ 14000 │ Grace (30000) │ Ivan (14000) │ 16000 │
│ Marketing │ Dave │ Marketing Director │ 32000 │ Dave (32000) │ Frank (16000) │ 0 │
│ Marketing │ Eve │ Marketing Specialist │ 18000 │ Dave (32000) │ Frank (16000) │ 14000 │
│ Marketing │ Frank │ Marketing Specialist │ 16000 │ Dave (32000) │ Frank (16000) │ 16000 │
└─────────────┴───────┴──────────────────────┴────────┴──────────────────┴──────────────────┴────────────┘
⚠️ Note:
LAST_VALUEby default only looks from the current row to the end of the partition (RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW). You must specifyROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWINGto get the true last value in the partition.
The gap_to_top column shows how far each employee is from their department’s top salary. Carol in Engineering has a $20,000 gap to the department maximum — plenty of room for growth!
4. Equal-Depth Bucketing: NTILE
Problem: Divide customers into 4 sales tiers
SELECT
salesperson,
SUM(amount) AS total_sales,
NTILE(4) OVER (ORDER BY SUM(amount) DESC) AS tier
FROM sales
GROUP BY salesperson
ORDER BY total_sales DESC;
Output:
┌────────────┬────────────┬──────┐
│ salesperson│ total_sales│ tier │
├────────────┼────────────┼──────┤
│ Dave │ 312000 │ 1 │
│ Alice │ 255000 │ 1 │
│ Eve │ 230000 │ 2 │
│ Bob │ 197000 │ 2 │
│ Frank │ 203000 │ 3 │
│ Carol │ 179000 │ 3 │
└────────────┴────────────┴──────┘
NTILE(4) splits 6 salespeople into 4 tiers as evenly as possible. Dave and Alice are Tier 1 — your top revenue generators.
5. Rolling Aggregates: SUM/AVG with OVER
Problem: Cumulative sales trends by region
SELECT
region,
month,
SUM(amount) AS monthly_total,
SUM(SUM(amount)) OVER (PARTITION BY region ORDER BY month) AS cumulative,
ROUND(AVG(SUM(amount)) OVER (PARTITION BY region ORDER BY month
ROWS BETWEEN 1 PRECEDING AND CURRENT ROW), 0) AS moving_avg_2m
FROM sales
GROUP BY region, month
ORDER BY region, month;
Output:
┌────────┬────────┬───────────────┬────────────┬───────────────┐
│ region │ month │ monthly_total │ cumulative │ moving_avg_2m │
├────────┼────────┼───────────────┼────────────┼───────────────┤
│ North │ 2026-01│ 303000 │ 303000 │ 303000 │
│ North │ 2026-02│ 328000 │ 631000 │ 315500 │
│ East │ 2026-01│ 360000 │ 360000 │ 360000 │
│ East │ 2026-02│ 385000 │ 745000 │ 372500 │
└────────┴────────┴───────────────┴────────────┴───────────────┘
Advanced: Window Functions + FILTER Clause
-- Cumulative high-value sales (> 100K) per salesperson
SELECT
salesperson,
month,
amount,
SUM(amount) FILTER (WHERE amount > 100000) OVER (
PARTITION BY salesperson ORDER BY month
) AS cumulative_high_value
FROM sales
ORDER BY salesperson, month;
6. Window Functions vs Subqueries: Performance
Let’s check DuckDB’s execution plan for both approaches:
-- Window function version
EXPLAIN ANALYZE
SELECT *, RANK() OVER (PARTITION BY region ORDER BY amount DESC) AS r
FROM sales;
-- Correlated subquery version
EXPLAIN ANALYZE
SELECT s.*, (
SELECT COUNT(*) + 1 FROM sales s2
WHERE s2.region = s.region AND s2.amount > s.amount
) AS r
FROM sales s;
The window function version uses one scan + sort, while the subquery version requires N correlated subqueries (cartesian product). On million-row datasets, window functions are typically 10-100x faster.
DuckDB optimization note: DuckDB has specialized optimization for window functions — it prefers pipelined execution over materializing the entire window, especially when the
ORDER BYandPARTITION BYcolumns already have a known order.
Summary
| Window Function | Business Use Case | Key Syntax |
|---|---|---|
RANK / DENSE_RANK / ROW_NUMBER | Top N analysis, tie handling | PARTITION BY ... ORDER BY ... |
LAG / LEAD | MoM/YoY comparison, offset analysis | LAG(col, n) for offset |
FIRST_VALUE / LAST_VALUE | Partition extremes, boundary values | Must specify ROWS BETWEEN frame |
NTILE | Equal-depth bucketing, customer tiers | NTILE(n) for bucket count |
SUM/AVG ... OVER | Running totals, moving averages | ROWS BETWEEN ... PRECEDING AND ... FOLLOWING |
Window functions are the bridge between SQL as a “query language” and SQL as an “analytics language.” Master them, and you’ll write one elegant query where you used to write multiple subqueries and temp tables.
Next up: DuckDB Time Series Analysis — date_trunc, generate_series, and rolling window aggregations for time-dimensioned data.
For more DuckDB in Action guides, follow Olap Studio (duckdblab.org)