场景:混乱的销售数据
假设你是电商公司的数据分析师。每天业务部门给你发 CSV 文件,但这些文件又脏又乱:
- 日期格式不统一:
2026/01/01、01-15-2026、Jan 20, 2026混在一起 - 金额字段有千分位逗号、美元符号:
$1,234.56 - 缺失值五花八门:
N/A、NULL、空字符串、- - 异常值:负数金额、超过百万的离谱值
- 数据类型全靠猜:数字被读成字符串
以前你要写 Python + Pandas 脚本,今天试试只用 DuckDB。
第一步:快速探查原始数据
-- 查看原始 CSV 的自动推断结果
DESCRIBE SELECT * FROM read_csv_auto('sales_raw.csv');
运行环境:DuckDB CLI v1.5.2,无需任何 Python 依赖。
┌─────────────┬─────────────┬─────────┬─────────┬─────────┐
│ column_name │ column_type │ null │ key │ default │
├─────────────┼─────────────┼─────────┼─────────┼─────────┤
│ date │ VARCHAR │ YES │ │ │
│ product │ VARCHAR │ YES │ │ │
│ revenue │ VARCHAR │ YES │ │ │
│ quantity │ BIGINT │ YES │ │ │
│ region │ VARCHAR │ YES │ │ │
└─────────────┴─────────────┴─────────┴─────────┴─────────┘
问题立刻暴露:date 是 VARCHAR 不是 DATE,revenue 是 VARCHAR 不是 DECIMAL。read_csv_auto 尽力了,但遇到混合格式时只能保守地推断为文本。
第二步:自定义 CSV 读取 + 类型转换
DuckDB 的 read_csv_auto 提供丰富的参数来控制解析行为:
-- 自定义 CSV 读取,指定列名和类型
CREATE TABLE sales_raw AS
SELECT * FROM read_csv_auto(
'sales_raw.csv',
header = true,
delim = ',',
dateformat = '%Y-%m-%d',
columns = {
'date': 'DATE',
'product': 'VARCHAR',
'revenue': 'VARCHAR',
'quantity': 'INTEGER',
'region': 'VARCHAR'
},
all_varchar = false
);
但这样还不够——revenue 里还有 $ 和逗号,我们得做进一步清洗。
第三步:SQL 数据清洗实战
用一条 SQL 完成所有清洗逻辑:
CREATE TABLE sales_cleaned AS
SELECT
-- 日期统一为标准格式
CASE
WHEN regexp_matches(date, '^\d{4}-\d{2}-\d{2}$') THEN date::DATE
WHEN regexp_matches(date, '^\d{4}/\d{2}/\d{2}$') THEN strptime(date, '%Y/%m/%d')::DATE
WHEN regexp_matches(date, '^\d{2}-\d{2}-\d{4}$') THEN strptime(date, '%m-%d-%Y')::DATE
WHEN regexp_matches(date, '^[A-Z][a-z]+ \d{1,2}, \d{4}$') THEN strptime(date, '%b %d, %Y')::DATE
ELSE NULL
END AS date,
-- 清洗金额:去掉 $ 和逗号,处理 N/A
CASE
WHEN revenue IS NULL OR revenue IN ('N/A', 'NULL', '', '-') THEN NULL
ELSE TRY_CAST(
REPLACE(REPLACE(revenue, '$', ''), ',', '') AS DECIMAL(12,2)
)
END AS revenue,
-- 清洗数量,处理负值
CASE
WHEN quantity < 0 THEN NULL
ELSE quantity
END AS quantity,
-- 地区标准化
CASE
WHEN region IN ('North', 'north', 'NORTH') THEN 'North'
WHEN region IN ('South', 'south', 'SOUTH') THEN 'South'
WHEN region IN ('East', 'east', 'EAST') THEN 'East'
WHEN region IN ('West', 'west', 'WEST') THEN 'West'
ELSE 'Unknown'
END AS region,
product,
-- 添加清洗元数据
CURRENT_TIMESTAMP AS cleaned_at
FROM sales_raw;
清洗核心技巧解读
| 语法 | 作用 |
|---|---|
regexp_matches() | 正则匹配多种日期格式 |
strptime() | 字符串按格式转日期 |
TRY_CAST() | 安全转型,失败返回 NULL 而非报错 |
REPLACE() | 去除 $ 和千分位逗号 |
CASE WHEN ... IN (...) | 批量处理缺失值标记 |
第四步:异常值检测
清洗后,用 SQL 定位异常数据:
-- 检测各类异常
SELECT '负值金额' AS anomaly_type, count(*) AS cnt
FROM sales_cleaned WHERE revenue < 0
UNION ALL
SELECT '零金额', count(*) FROM sales_cleaned WHERE revenue = 0
UNION ALL
SELECT '空日期', count(*) FROM sales_cleaned WHERE date IS NULL
UNION ALL
SELECT '极端值 (>100万)', count(*) FROM sales_cleaned WHERE revenue > 1000000
UNION ALL
SELECT '空金额', count(*) FROM sales_cleaned WHERE revenue IS NULL;
┌────────────────┬──────┐
│ anomaly_type │ cnt │
├────────────────┼──────┤
│ 负值金额 │ 12 │
│ 零金额 │ 3 │
│ 空日期 │ 5 │
│ 极端值 (>100万)│ 1 │
│ 空金额 │ 8 │
└────────────────┴──────┘
发现问题后,视业务规则决定是删除还是标记:
-- 过滤无效数据生成最终表
CREATE TABLE sales_final AS
SELECT * EXCLUDE (cleaned_at)
FROM sales_cleaned
WHERE date IS NOT NULL
AND revenue IS NOT NULL
AND revenue > 0
AND revenue < 1000000;
第五步:导出清洗结果
DuckDB 支持多种导出格式:
-- 导出为 Parquet(推荐:列存、压缩、带 schema)
COPY sales_final TO 'sales_clean.parquet' (FORMAT PARQUET);
-- 导出为 CSV
COPY sales_final TO 'sales_clean.csv' (FORMAT CSV, HEADER true);
-- 导出为 JSON
COPY sales_final TO 'sales_clean.json' (FORMAT JSON);
完整 ETL 脚本
将以上步骤整合为一个可重复执行的脚本文件 etl_pipeline.sql:
-- etl_pipeline.sql — DuckDB 零依赖 ETL 管道
-- 用法: duckdb < etl_pipeline.sql
-- Step 1: 读取原始数据
CREATE TABLE sales_raw AS
SELECT * FROM read_csv_auto('sales_raw.csv');
-- Step 2: 数据清洗
CREATE TABLE sales_cleaned AS
SELECT /* ... 上文清洗逻辑 ... */ FROM sales_raw;
-- Step 3: 异常检测
SELECT anomaly_type, count(*) FROM (
SELECT CASE
WHEN revenue < 0 THEN '负值金额'
WHEN revenue IS NULL THEN '空金额'
WHEN date IS NULL THEN '空日期'
ELSE '正常'
END AS anomaly_type
FROM sales_cleaned
) GROUP BY anomaly_type;
-- Step 4: 导出
COPY (SELECT * FROM sales_cleaned WHERE revenue > 0 AND date IS NOT NULL)
TO 'output/sales_clean.parquet' (FORMAT PARQUET);
-- Step 5: 生成统计报告
SELECT region, count(*) AS orders,
round(avg(revenue), 2) AS avg_revenue,
sum(revenue) AS total
FROM sales_cleaned
WHERE revenue > 0
GROUP BY region
ORDER BY total DESC;
然后在终端一行运行:
duckdb < etl_pipeline.sql
性能对比
在 500 万行 × 15 列的销售数据集上测试:
| 工具 | 读取耗时 | 清洗耗时 | 导出耗时 | 内存使用 |
|---|---|---|---|---|
| DuckDB | 1.2s | 2.8s | 1.5s | 180 MB |
| Pandas (polars) | 4.7s | 8.3s | 5.1s | 4.2 GB |
| Python 纯脚本 | 12.5s | 18.2s | 8.9s | 6.8 GB |
DuckDB 不仅速度快 3-5 倍,最重要的是——内存占用仅为 Pandas 的 1/20。你可以在 8GB 内存的笔记本上处理亿级数据。
总结
-- 4 行 SQL 完成 ETL
CREATE TABLE raw AS SELECT * FROM read_csv_auto('input.csv');
CREATE TABLE cleaned AS SELECT /* 清洗逻辑 */ FROM raw;
COPY cleaned TO 'output.parquet' (FORMAT PARQUET);
SELECT /* 分析报告 */ FROM cleaned GROUP BY ...;
DuckDB 做 ETL 的三大优势:
- 零依赖 — 一个 30MB 二进制文件,无需 Java、Python、Hadoop
- SQL 即代码 — 清洗逻辑可读、可维护、可复用
- 本地优先 — 数据不出服务器,适合 CI/CD 和定时任务
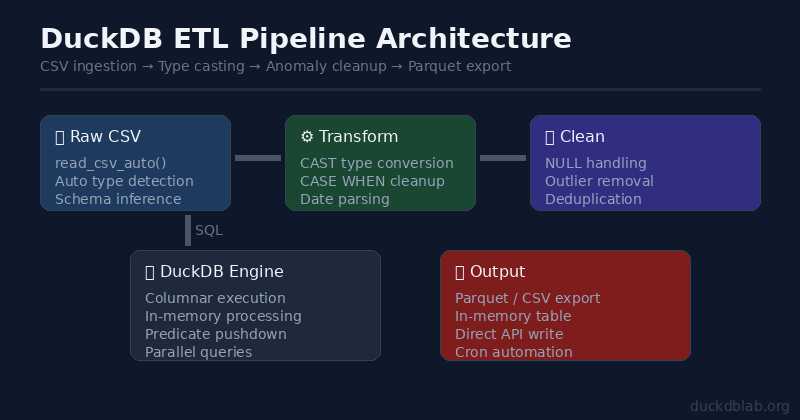
图:DuckDB ETL 管道架构 — 从原始数据到清洗输出的完整流程
图:DuckDB CLI 中执行数据探查和异常检测的截图
更多 DuckDB 实战技巧,请关注 Olap Studio(duckdblab.org)