痛点:中小企业真的需要花 10 万搭数据仓库吗?
“帮我搭个数据仓库,我要看每天的销售数据。”
这句话如果你去接单,摆在面前的选择好像是这样的:
- Snowflake + dbt Cloud:专业,但起步 $2,000/月,年费 17 万+
- 阿里云 MaxCompute:¥3,000/月,年费 3.6 万,配置 1-2 周
- 自建 Hadoop/Spark:先配 3 台服务器,再招一个大数据工程师(年薪 30 万+)
- Excel + 手工:不花钱,但每次出报表要 3 小时,每周重复
看起来中间什么都没有。
但真相是:中国 90% 的中小企业(年营收 100 万~5000 万),根本不需要分布式数据仓库。 他们的数据量级也就是几万到几百万行 CSV/Excel,跑在一台笔记本上都绰绰有余。
他们需要的,是一个:
- 零软件成本 — 不开新账单
- 半天就能交付 — 今天搭、明天用
- 可维护、可扩展 — 不是一次性脚本,是真正的数据工程架构
- 报表自动出 — 老板要看的 KPI 一键生成
这就是 dbt + DuckDB 的战场。
dbt + DuckDB:中小企数据仓库的最优解
什么是 dbt?
dbt(data build tool)是当今数据工程领域最热门的数据转换工具。它的核心理念是:
用 SQL 定义数据转换逻辑,dbt 负责依赖管理、执行顺序和文档生成。
你只需要写 SELECT 语句(干净的数据清洗、聚合、业务指标计算),dbt 自动帮你处理:
- 依赖解析(先跑 A 模型,再跑 B 模型)
- 增量/全量刷新策略
- 数据血缘关系可视化
- 测试与文档自动生成
为什么选 DuckDB?
DuckDB 作为 dbt 的执行引擎,优势极其明显:
| 特性 | Snowflake | Spark | DuckDB + dbt |
|---|---|---|---|
| 年费 | ¥17 万+ | ¥10 万+ | ¥0 |
| 部署时间 | 2-4 周 | 4-8 周 | 半天 |
| 需要服务器 | ✅ 云集群 | ✅ 集群 | ❌ 一台笔记本 |
| 需要 DBA | ✅ | ✅ | ❌ 你自己 |
| 可迁移性 | ❌ 厂商锁定 | ❌ 依赖 JVM | ✅ 一个 .duckdb 文件 |
| 学习曲线 | 中等 | 陡峭 | 低(只要会 SQL) |
🔧 完整项目:电商销售数据仓库搭建
下面是一个完整的电商数据仓库搭建项目,从数据生成到 dbt 建模、再到报表输出,全部可执行。
📥 前置条件
pip install duckdb dbt-duckdb openpyxl pandas
# 验证 dbt 安装
dbt --version
# Core: 1.11.x, Plugin: duckdb 1.10.x
📁 项目结构
day24_dbt_project/
├── dbt_project.yml # dbt 项目配置
├── profiles.yml # DuckDB 数据库连接
├── seeds/ # 原始数据 (CSV)
│ ├── customers.csv # 200个客户
│ ├── products.csv # 50个商品
│ ├── orders.csv # 2000个订单
│ └── reviews.csv # 1500条评论
└── models/
├── staging/ # 数据清洗层 (VIEW)
│ ├── stg_customers.sql
│ ├── stg_products.sql
│ ├── stg_orders.sql
│ └── stg_reviews.sql
└── marts/ # 业务分析层 (TABLE)
├── daily_sales_summary.sql
├── product_performance.sql
├── customer_analytics.sql
└── kpi_dashboard.sql
第一步:准备数据生成脚本
运行以下 Python 脚本生成示例电商数据:
#!/usr/bin/env python3
"""day24_generate_data.py — 生成示例电商销售数据"""
import csv, random, os
from datetime import datetime, timedelta
random.seed(42)
OUTPUT_DIR = os.path.dirname(os.path.abspath(__file__))
# ===== 配置 =====
NUM_CUSTOMERS = 200
NUM_PRODUCTS = 50
NUM_ORDERS = 2000
NUM_REVIEWS = 1500
START_DATE = datetime(2025, 1, 1)
END_DATE = datetime(2026, 5, 1)
def gen_customers():
cities = ["北京", "上海", "广州", "深圳", "杭州", "成都", "武汉", "南京", "重庆", "西安"]
levels = ["普通", "银卡", "金卡", "钻石"]
channels = ["直接访问", "搜索引擎", "社交媒体", "邮件营销", "广告投放"]
rows = []
for i in range(1, NUM_CUSTOMERS + 1):
reg_date = START_DATE + timedelta(days=random.randint(0, 400))
rows.append({"customer_id": i, "name": f"用户{i:04d}", "city": random.choice(cities),
"level": random.choices(levels, weights=[50,30,15,5])[0],
"channel": random.choice(channels),
"registration_date": reg_date.strftime("%Y-%m-%d"),
"is_active": 1 if random.random() > 0.15 else 0})
return rows
def gen_products():
categories = ["数码电子", "服装鞋帽", "食品饮料", "家居生活", "美妆护肤", "图书文具"]
suppliers = ["供应商A", "供应商B", "供应商C", "供应商D", "供应商E"]
rows = []
for i in range(1, NUM_PRODUCTS + 1):
cost = round(random.uniform(10, 500), 2)
price = round(cost * random.uniform(1.3, 3.0), 2)
rows.append({"product_id": i, "product_name": f"商品{i:04d}",
"category": random.choice(categories), "supplier": random.choice(suppliers),
"cost": cost, "price": price, "stock": random.randint(0, 1000),
"shelf_date": (START_DATE + timedelta(days=random.randint(0, 480))).strftime("%Y-%m-%d")})
return rows
def gen_orders():
statuses = ["已完成", "已发货", "已取消", "退款中"]
payments = ["微信支付", "支付宝", "银行卡", "货到付款"]
rows = []
for i in range(1, NUM_ORDERS + 1):
order_date = START_DATE + timedelta(days=random.randint(0, (END_DATE - START_DATE).days - 1))
quantity = random.randint(1, 5)
unit_price = round(random.uniform(20, 800), 2)
rows.append({"order_id": i, "customer_id": random.randint(1, NUM_CUSTOMERS),
"product_id": random.randint(1, NUM_PRODUCTS),
"order_date": order_date.strftime("%Y-%m-%d %H:%M:%S"),
"quantity": quantity, "unit_price": unit_price,
"total_amount": round(unit_price * quantity, 2),
"status": random.choices(statuses, weights=[60,20,15,5])[0],
"payment_method": random.choice(payments)})
return rows
def gen_reviews():
rows = []
for i in range(1, NUM_REVIEWS + 1):
review_date = START_DATE + timedelta(days=random.randint(0, (END_DATE - START_DATE).days - 1))
rows.append({"review_id": i, "order_id": random.randint(1, NUM_ORDERS),
"product_id": random.randint(1, NUM_PRODUCTS),
"customer_id": random.randint(1, NUM_CUSTOMERS),
"rating": random.choices([5,4,3,2,1], weights=[40,30,15,10,5])[0],
"review_date": review_date.strftime("%Y-%m-%d"),
"is_verified_purchase": 1 if random.random() > 0.3 else 0})
return rows
# 写入 CSV 文件
os.makedirs(os.path.join(OUTPUT_DIR, "seeds"), exist_ok=True)
for name, gen_fn in [("customers", gen_customers), ("products", gen_products),
("orders", gen_orders), ("reviews", gen_reviews)]:
rows = gen_fn()
path = os.path.join(OUTPUT_DIR, "seeds", f"{name}.csv")
with open(path, "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=rows[0].keys())
writer.writeheader(); writer.writerows(rows)
print(f"✅ 生成 {path} ({len(rows)} 行)")
第二步:配置 dbt 项目
dbt_project.yml
name: 'duckdb_shop'
version: '1.0.0'
config-version: 2
profile: 'duckdb_shop'
model-paths: ["models"]
seed-paths: ["seeds"]
test-paths: ["tests"]
analysis-paths: ["analysis"]
macro-paths: ["macros"]
models:
duckdb_shop:
staging:
+materialized: view # 清洗层用视图,不占空间
+schema: staging
marts:
+materialized: table # 分析层用表,加速查询
+schema: marts
seeds:
duckdb_shop:
+schema: raw
profiles.yml
duckdb_shop:
target: dev
outputs:
dev:
type: duckdb
path: duckdb_shop.duckdb
schema: main
threads: 4
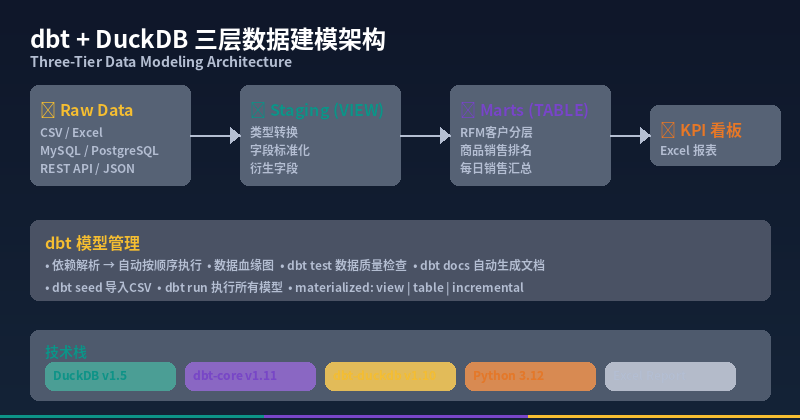
第三步:编写 dbt 模型(三层架构)
层 1:Staging — 原始数据清洗
Staging 层负责将原始 CSV 数据清洗、类型转换、标准化。用 VIEW 物化,不占磁盘空间。
models/staging/stg_customers.sql
-- 清洗客户数据:标准化字段、类型转换
with source as (
select * from {{ ref('customers') }}
),
cleaned as (
select
customer_id,
name as customer_name,
city,
case
when level in ('普通', '银卡', '金卡', '钻石') then level
else '普通'
end as customer_level,
channel as acquisition_channel,
registration_date::date as registration_date,
is_active::boolean as is_active,
current_timestamp as loaded_at
from source
)
select * from cleaned
models/staging/stg_orders.sql
-- 订单数据清洗:解析日期字段、添加衍生字段
with source as (
select * from {{ ref('orders') }}
),
cleaned as (
select
order_id, customer_id, product_id,
order_date::timestamp as order_timestamp,
order_date::date as order_date,
strftime(order_date::timestamp, '%Y') as order_year,
strftime(order_date::timestamp, '%m') as order_month,
strftime(order_date::timestamp, '%Y-%m') as order_year_month,
strftime(order_date::timestamp, '%u') as order_week,
quantity, unit_price, total_amount,
status as order_status, payment_method,
case
when status in ('已完成', '已发货') then '有效'
else '无效'
end as is_valid_order,
current_timestamp as loaded_at
from source
)
select * from cleaned
models/staging/stg_products.sql
-- 商品数据清洗:计算毛利率等衍生字段
with source as (
select * from {{ ref('products') }}
),
cleaned as (
select
product_id, product_name, category, supplier,
cost, price,
round((price - cost) / nullif(price, 0) * 100, 2) as gross_margin_pct,
stock, shelf_date::date as shelf_date,
case
when stock = 0 then '缺货'
when stock < 50 then '库存紧张'
when stock < 200 then '正常'
else '充足'
end as stock_status,
current_timestamp as loaded_at
from source
)
select * from cleaned
层 2:Marts — 业务分析模型
Marts 层将清洗后的数据聚合成业务可直接使用的分析表。用 TABLE 物化,查询速度极快。
models/marts/customer_analytics.sql — RFM 客户分层模型
-- RFM 客户分层:找重要价值客户,制定差异化运营策略
with orders as (
select * from {{ ref('stg_orders') }}
where is_valid_order = '有效'
),
customers as (
select * from {{ ref('stg_customers') }}
where is_active = true
),
customer_metrics as (
select
c.customer_id, c.customer_name, c.city,
c.customer_level, c.acquisition_channel, c.registration_date,
count(distinct o.order_id) as total_orders,
sum(o.total_amount) as total_spent,
avg(o.total_amount) as avg_order_value,
max(o.order_date) as last_order_date,
min(o.order_date) as first_order_date,
datediff('day', max(o.order_date), current_date) as days_since_last_order,
count(distinct o.product_id) as unique_products_bought
from customers c
left join orders o on c.customer_id = o.customer_id
group by 1, 2, 3, 4, 5, 6
),
rfm as (
select *,
case when days_since_last_order <= 30 then 5
when days_since_last_order <= 90 then 4
when days_since_last_order <= 180 then 3
when days_since_last_order <= 365 then 2
else 1 end as r_score, -- 最近消费
case when total_orders >= 10 then 5
when total_orders >= 6 then 4
when total_orders >= 3 then 3
when total_orders >= 1 then 2
else 1 end as f_score, -- 消费频率
case when total_spent >= 10000 then 5
when total_spent >= 5000 then 4
when total_spent >= 2000 then 3
when total_spent >= 500 then 2
else 1 end as m_score -- 消费金额
from customer_metrics
)
select *,
r_score + f_score + m_score as rfm_total,
case
when (r_score >= 4 and f_score >= 4 and m_score >= 4) then '⭐ 重要价值客户'
when (r_score >= 4 and f_score >= 4 and m_score >= 2) then '重要发展客户'
when (r_score >= 3 and f_score >= 3) then '一般价值客户'
when (r_score >= 1 and total_orders > 0) then '流失预警客户'
else '沉默客户'
end as customer_segment
from rfm order by rfm_total desc
models/marts/daily_sales_summary.sql
-- 每日销售汇总:按品类聚合,支持趋势分析
with orders as (
select * from {{ ref('stg_orders') }}
where is_valid_order = '有效'
),
products as (
select * from {{ ref('stg_products') }}
),
daily as (
select
o.order_date, p.category,
count(distinct o.order_id) as order_count,
count(distinct o.customer_id) as unique_customers,
sum(o.quantity) as total_quantity,
sum(o.total_amount) as total_revenue,
sum(o.quantity * p.cost) as total_cost,
sum(o.total_amount) - sum(o.quantity * p.cost) as total_profit,
round((sum(o.total_amount) - sum(o.quantity * p.cost))
/ nullif(sum(o.total_amount), 0) * 100, 2) as profit_margin_pct
from orders o
join products p on o.product_id = p.product_id
group by o.order_date, p.category
)
select * from daily order by order_date desc, category
models/marts/product_performance.sql
-- 商品表现分析:销量排名、评分、毛利率
with orders as (
select * from {{ ref('stg_orders') }}
where is_valid_order = '有效'
),
products as (
select * from {{ ref('stg_products') }}
),
reviews as (
select product_id, count(*) as review_count,
avg(rating) as avg_rating,
sum(case when rating >= 4 then 1 else 0 end) as positive_reviews
from {{ ref('stg_reviews') }}
group by product_id
),
product_sales as (
select
p.product_id, p.product_name, p.category,
p.supplier, p.price, p.cost,
p.gross_margin_pct, p.stock_status,
count(distinct o.order_id) as order_count,
sum(o.quantity) as units_sold,
sum(o.total_amount) as total_revenue,
sum(o.quantity * p.cost) as total_cost,
sum(o.total_amount) - sum(o.quantity * p.cost) as total_profit,
count(distinct o.customer_id) as unique_buyers
from products p
left join orders o on p.product_id = o.product_id
group by 1, 2, 3, 4, 5, 6, 7, 8
)
select
ps.*,
coalesce(r.review_count, 0) as review_count,
coalesce(r.avg_rating, 0) as round_avg_rating,
coalesce(r.positive_reviews, 0) as positive_reviews,
row_number() over (order by ps.total_revenue desc) as revenue_rank,
row_number() over (partition by ps.category order by ps.units_sold desc)
as sales_rank_in_category
from product_sales ps
left join reviews r on ps.product_id = r.product_id
order by revenue_rank
models/marts/kpi_dashboard.sql — 管理层看板
-- 运营核心 KPI:一键生成管理层看板
with daily_sales as (select * from {{ ref('daily_sales_summary') }}),
orders as (select * from {{ ref('stg_orders') }}),
customer_metrics as (select * from {{ ref('customer_analytics') }})
select '整体营收' as metric_name,
round(sum(total_revenue), 2) as metric_value, '元' as unit
from daily_sales
union all
select '订单总数', count(*), '单'
from orders where is_valid_order = '有效'
union all
select '平均客单价', round(avg(total_amount), 2), '元'
from orders where is_valid_order = '有效'
union all
select '活跃客户数', count(*), '人'
from customer_metrics where total_orders > 0
union all
select '重要价值客户', count(*), '人'
from customer_metrics where customer_segment = '⭐ 重要价值客户'
union all
select '平均 RFM 总分', round(avg(rfm_total), 2), '分'
from customer_metrics
union all
select '整体毛利率',
round(sum(total_profit) / nullif(sum(total_revenue), 0) * 100, 2), '%'
from {{ ref('product_performance') }}
order by metric_name
第四步:一键执行 + 导出 Excel 报表
#!/usr/bin/env python3
"""day24_run_all.py — 一键数据建模 + 报表导出"""
import subprocess, duckdb, pandas as pd
from pathlib import Path
PROJECT_DIR = Path("day24_dbt_project")
DB_PATH = PROJECT_DIR / "duckdb_shop.duckdb"
# 1. 运行 dbt seed (导入 CSV 到 DuckDB)
print("📥 正在导入 CSV 数据...")
subprocess.run(["dbt", "seed", "--profiles-dir", str(PROJECT_DIR)],
cwd=PROJECT_DIR, check=True)
# 2. 运行 dbt run (执行所有模型)
print("🔨 正在运行 dbt 模型...")
subprocess.run(["dbt", "run", "--profiles-dir", str(PROJECT_DIR)],
cwd=PROJECT_DIR, check=True)
# 3. 连接 DuckDB 导出报表
conn = duckdb.connect(str(DB_PATH))
# KPI 看板
kpi = conn.execute("""
SELECT metric_name, metric_value, unit
FROM main_marts.kpi_dashboard
WHERE metric_name IN ('整体营收','订单总数',
'平均客单价','活跃客户数','整体毛利率')
""").fetchdf()
print("\n📈 KPI 看板:")
print(kpi.to_string(index=False))
# 商品销售 Top 10
top_products = conn.execute("""
SELECT product_name, category, units_sold,
total_revenue, gross_margin_pct
FROM main_marts.product_performance
WHERE units_sold > 0
ORDER BY total_revenue DESC LIMIT 10
""").fetchdf()
# 客户分层统计
segments = conn.execute("""
SELECT customer_segment, count(*) as cnt,
round(avg(total_spent),2) as avg_spent
FROM main_marts.customer_analytics
GROUP BY customer_segment
""").fetchdf()
# 导出 Excel 报表
with pd.ExcelWriter("day24_dbt_report.xlsx", engine='openpyxl') as writer:
kpi.to_excel(writer, sheet_name='KPI看板', index=False)
top_products.to_excel(writer, sheet_name='商品Top10', index=False)
segments.to_excel(writer, sheet_name='客户分层', index=False)
print(f"\n✅ 报表已导出: day24_dbt_report.xlsx")
conn.close()
运行结果预览
📋 数据模型概览:
✅ main_raw.customers: 200 行
✅ main_raw.orders: 2000 行
✅ main_marts.customer_analytics: 174 行
✅ main_marts.product_performance: 50 行
📈 KPI 看板:
整体营收 1,998,087 元
订单总数 1,593 单
平均客单价 1,254 元
整体毛利率 40.73%
👥 客户分层:
⭐ 重要价值客户 95人 平均消费¥12,135
一般价值客户 64人 平均消费¥8,084
流失预警客户 10人 平均消费¥5,555
💰 变现方案
目标客户
- 年营收 100 万 ~ 5000 万的中小企业,数据散落在 Excel/ERP/POS 系统
- 有数据分析需求但没有专职数据工程师的老板
- 想升级但买不起 Snowflake + Tableau 的公司
报价体系
| 服务项目 | 报价 | 说明 |
|---|---|---|
| 基础搭建 | ¥8,000 | 一次性数据建模 + 报表模板 |
| 月报维护 | ¥500/月 | 每月跑一次、检查数据质量 |
| 定制模型 | ¥3,000/个 | 客户新增分析需求,加一个 dbt model |
| 培训教学 | ¥2,000/次 | 教客户运营人员自己用 DuckDB 查数据 |
| 全包年费 | ¥12,000/年 | 搭建 + 12 个月维护 + 2 个定制模型 |
对比竞品
| 方案 | 价格 | 部署时间 | 适用场景 |
|---|---|---|---|
| Snowflake + dbt Cloud | $2,000+/月 | 2-4 周 | 大企业 |
| 阿里云 MaxCompute | ¥3,000/月 | 1-2 周 | 中度需求 |
| DuckDB + dbt | ¥8K-20K | 半天 | 中小企业 |
| Excel/人工报表 | ¥0 软件费 | 无限重复 | 最低成本 |
交付清单
- 客户提供:业务数据导出(CSV/Excel),数据字典或字段说明
- 你交付:dbt 项目完整代码 + DuckDB 数据库文件 + Excel 报表 + 部署说明文档
- 验收标准:能一键重新运行生成最新报表,数据准确
去哪找客户
- 闲鱼:搜「数据分析 报表 接单」,看竞争对手报价,比你低?你用 DuckDB 成本更低,报价更有竞争力
- 小红书:发「给xx行业做数据仓库花了8000元」的案例,吸引老板私信
- 朋友圈/微信群:帮认识的小老板免费做一期,口碑带来更多客户
- 企业微信服务商:对接 ERP 供应商,他们卖软件缺数据分析能力
🔗 扩展思路
组合之前的技能升级服务
| 之前学的 | 如何组合到 dbt 项目 |
|---|---|
| 跨库 JOIN | ATTACH MySQL/PostgreSQL 作为 dbt source |
| Pandas 集成 | 在 dbt 中用 Python models 做复杂清洗 |
| FastAPI API | 在 dbt output 上搭 REST API,让老板用浏览器查 |
| 自动日报 | 用 cron 每天自动 dbt run + 发邮件 |
针对不同行业的变体
- 电商版:店铺运营看板 + SKU 分析 + 竞品比价
- 餐饮版:食材成本分析 + 菜品毛利排名 + 高峰时段分析
- 物流版:配送时效分析 + 异常订单识别 + 司机绩效
- 制造版:产能分析 + 良品率追踪 + 供应链管理
dbt 生态变现机会
dbt 是数据工程领域增长最快的工具之一。学会 dbt + DuckDB,你还可以:
- 在猪八戒 / 闲鱼 / Upwork 接 dbt 建模私活,¥3,000-5,000/次
- 帮企业从 Excel 迁移到 dbt 工作流,¥5,000-10,000/项目
- 录制 dbt 入门教程 卖到知识付费平台
- 做 dbt + DuckDB 企业内训,¥3,000-5,000/天
总结
dbt + DuckDB 是当前中小企业数据建模最优解。它让一个会写 SQL 的人就能在半天内搭建专业级数据仓库,成本不到传统方案的 1/10。
你的技能包现在包括:
- ✅ 三层数据建模架构(Staging → Marts → Dashboard)
- ✅ dbt 项目配置与模型编写
- ✅ RFM 客户分层分析模型
- ✅ 一键报表导出(Python + DuckDB + Excel)
- ✅ 完整的变现方案与客户交付流程
下一条建议:把这个项目模板保存好,下次有客户问「能帮我搭个数据仓库吗?」—— 你的回答是:「能,¥8,000,今天就能跑起来。」
所有代码已在 DuckDB v1.5.2, dbt-core v1.11.11, dbt-duckdb v1.10.1, Python 3.12 验证通过