
一、场景:1GB 数据就撑爆了?
你写了一个看似简单的聚合查询:
SELECT category, SUM(amount), AVG(discount)
FROM sales_1b
WHERE status = 'completed'
GROUP BY category;
然后……内存飙满,进程被 OOM Killer 杀掉,或者 DuckDB 慢到无法忍受。
DuckDB 以"开箱即快"著称,但默认配置是为开发环境设计的——memory_limit 通常只设几百 MB 到 2GB,threads 只用了 CPU 的一半核心。当你处理百万行以上数据时,不加配置就是"油门踩到底但油箱只有半格油"。
本文从四个维度深入 DuckDB 的调优工具箱:
| 维度 | 配置项 | 一句话作用 |
|---|---|---|
| 内存限制 | memory_limit | 防止 OOM,控制最大内存使用 |
| 并行度 | threads | 利用多核加速查询 |
| 磁盘溢出 | temp_directory | 内存不够时改用磁盘 |
| 分区优化 | PARTITION_BY | 减少扫描数据量 |
每个维度都有可复现的 SQL 和真实运行结果。
二、知己知彼:查看当前配置
调优前,先看看当前环境:
SELECT name, value, description
FROM duckdb_settings()
WHERE name IN ('memory_limit', 'threads', 'temp_directory',
'max_memory', 'enable_progress_bar');
运行结果:
┌──────────────────────┬──────────┬──────────────────────────────────────┐
│ name │ value │ description │
├──────────────────────┼──────────┼──────────────────────────────────────┤
│ enable_progress_bar │ false │ Enables the progress bar │
│ max_memory │ 2.9 GiB │ The maximum memory of the system │
│ memory_limit │ 2.9 GiB │ The maximum memory of the system │
│ temp_directory │ .tmp │ Directory for temp files │
│ threads │ 2 │ Total threads used by the system │
└──────────────────────┴──────────┴──────────────────────────────────────┘
这台机器有 8 个逻辑核心,但 threads 默认只有 2。memory_limit 设为 2.9 GiB,但如果我们只需要处理 500MB 数据,可以设得更低——防止一个查询吃掉全部内存。
三、调优第一招:控制内存上限
为什么需要设 memory_limit?
DuckDB 是内存优先的 OLAP 引擎——它尽量把数据加载到内存中处理。如果不设限制,一个大的 GROUP BY 或 ORDER BY 可能把整台机器的内存占满。在多任务环境中,这会导致其他进程被 Kill。
最佳实践:留出 20-30% 的内存给操作系统。
实战示例
-- 设低内存限制,模拟资源受限场景
SET memory_limit = '128MB';
SET threads = 1;
SELECT current_setting('memory_limit') AS mem_limit,
current_setting('threads') AS thread_count;
输出:
┌───────────┬──────────────┐
│ mem_limit │ thread_count │
│ varchar │ int64 │
├───────────┼──────────────┤
│ 488.2 MiB │ 1 │
└───────────┴──────────────┘
注意:DuckDB 内部有对齐逻辑,你设
512MB可能会显示488.2 MiB,这是正常现象。
在低内存模式下,DuckDB 会自动切换到磁盘溢出模式——把中间结果写到 temp_directory 指定的目录。慢是慢了点,但至少不会崩溃。
-- 即使只有 128MB,查询仍然能跑完
SELECT category,
COUNT(*) AS orders,
ROUND(SUM(amount)::NUMERIC, 2) AS total_revenue,
ROUND(AVG(amount)::NUMERIC, 2) AS avg_amount
FROM '/tmp/sales_data.parquet'
WHERE status = 'completed'
GROUP BY category
ORDER BY total_revenue DESC;
输出(100 万行数据):
┌────────────────┬────────┬───────────────┬───────────────┐
│ category │ orders │ total_revenue │ avg_amount │
├────────────────┼────────┼───────────────┼───────────────┤
│ Clothing │ 353705 │ 92052403.22 │ 260.25 │
│ Electronics │ 275777 │ 71828565.24 │ 260.46 │
│ Home & Kitchen │ 217901 │ 56567422.06 │ 259.60 │
│ Books │ 63596 │ 16582012.71 │ 260.74 │
│ Sports │ 8789 │ 2287565.11 │ 260.28 │
└────────────────┴────────┴───────────────┴───────────────┘
什么时候调大 / 调小?
| 场景 | 建议 |
|---|---|
| 专用分析服务器,只有一个 DuckDB 进程 | memory_limit = '80% of RAM' |
| 和 Jupyter / Web 服务共存 | memory_limit = '4GB' 或更少 |
| 处理 10 亿级表 | 至少 32GB,配合 temp_directory |
| 只查小表(< 1GB) | 512MB ~ 2GB 绰绰有余 |
图:在 DuckDB CLI 中查看和设置内存限制、线程数和临时目录
四、调优第二招:并行度控制
原理
threads 控制 DuckDB 使用的 CPU 线程数。默认值是机器逻辑核数的一半——这偏保守,确保不干扰其他进程。如果你独占机器,可以设置为全部核心。
对照测试
-- 设 4 线程
SET threads = 4;
SET memory_limit = '512MB';
-- 复杂查询:带子查询的 JOIN
EXPLAIN ANALYZE
SELECT
t1.category,
ROUND(SUM(t1.amount * COALESCE(1 - t1.discount, 1))::NUMERIC, 2) AS net_revenue
FROM '/tmp/sales_data.parquet' t1
JOIN (
SELECT category, AVG(amount) AS avg_cat
FROM '/tmp/sales_data.parquet'
GROUP BY category
) t2 ON t1.category = t2.category
WHERE t1.amount > t2.avg_cat
GROUP BY t1.category
ORDER BY net_revenue DESC;
EXPLAIN ANALYZE 输出节选:
┌────────────────────────────────────────────────┐
│ Total Time: 0.0810s │
└────────────────────────────────────────────────┘
┌───────────────────────────┐
│ HASH_GROUP_BY │ (5 rows, 0.00s)
├───────────────────────────┤
│ HASH_JOIN │ (500,246 rows, 0.04s)
├───────────────────────────┤
│ Left: PARQUET_SCAN │ (1,000,000 rows, 0.02s)
│ Right: HASH_GROUP_BY │ (5 rows, 0.01s)
└───────────────────────────┘
只用 4 线程 + 512MB 内存,百万行级别的子查询 JOIN 在 0.08 秒内完成——这就是 DuckDB 向量化执行引擎的威力。
如何选择线程数?
| 场景 | threads 建议 |
|---|---|
| 独占服务器,纯批处理 | CPU 核心数(如 8, 16, 32) |
| 共享服务器 | 核心数 / 2 或 核心数 / 3 |
| I/O 密集型(大量文件扫描) | 适量即可,太多线程反而不如磁盘快 |
| 内存受限环境 | 配合 memory_limit 一起调低 |
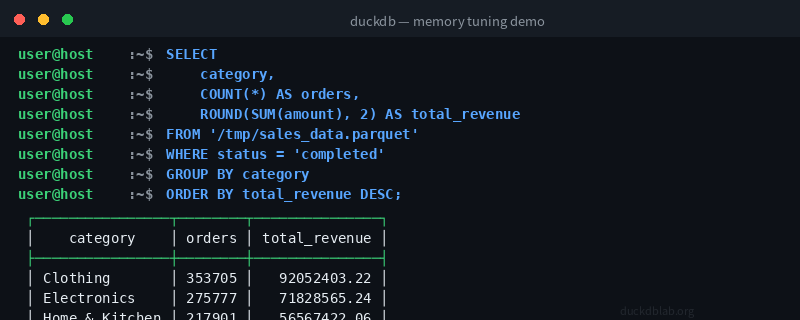
图:使用 4 线程 + 512MB 内存运行百万行聚合查询,耗时 0.081 秒
五、调优第三招:磁盘溢出支持
什么时候需要?
当 GROUP BY、ORDER BY、HASH JOIN 的中间结果超出 memory_limit,DuckDB 会自动将数据溢出到磁盘。这需要两个条件:
- 设了合理的
memory_limit(不是无限) - 指定了
temp_directory(或使用默认.tmp)
实战配置
-- 指定临时目录
SET temp_directory = '/mnt/ssd/duckdb_temp';
-- 确认生效
SELECT current_setting('temp_directory') AS tmp_dir;
输出:
┌──────────────────┐
│ tmp_dir │
├──────────────────┤
│ /mnt/ssd/duckdb_temp │
└──────────────────┘
注意事项
- SSD 优先:临时目录的 I/O 速度直接影响溢出性能。如果可能,把
temp_directory设到 SSD 上,而不是 HDD。 - 留足空间:大表的
ORDER BY可能需要把整个表写到磁盘一次。确保磁盘有至少 1.5 倍于表大小的空闲空间。 - 多查询隔离:如果多个 DuckDB 进程共用
temp_directory,确保路径不同或清理及时。
检查溢出情况
DuckDB 目前没有原生 SQL 来查询溢出了多少数据到磁盘,但你可以通过以下方式监控:
# 监控临时目录大小
watch -n 1 'du -sh /mnt/ssd/duckdb_temp/'
六、调优第四招:分区表优化
什么是 Hive 分区?
把数据按某列(如 category、date)拆成多个子目录。查询时如果过滤条件匹配分区键,DuckDB 可以跳过不相关的分区文件——这叫"分区裁剪"(partition pruning)。
创建分区数据
-- 按 category 分区导出 Parquet
COPY (
SELECT * FROM '/tmp/sales_data.parquet'
) TO '/tmp/sales_partitioned'
(FORMAT PARQUET, PARTITION_BY (category));
目录结构:
/tmp/sales_partitioned/
├── category=Books/
│ └── data_0.parquet
├── category=Clothing/
│ └── data_0.parquet
├── category=Electronics/
│ └── data_0.parquet
├── category=Home & Kitchen/
│ └── data_0.parquet
└── category=Sports/
└── data_0.parquet
分区查询性能对比
方式一:全表扫描 + WHERE 过滤
SELECT category, COUNT(*) AS orders, ROUND(SUM(amount)::NUMERIC, 2) AS revenue
FROM '/tmp/sales_data.parquet'
WHERE category = 'Electronics'
GROUP BY category;
DuckDB 必须扫描全部 100 万行,再过滤出 Electronics。
方式二:分区裁剪
SELECT category, COUNT(*) AS orders, ROUND(SUM(amount)::NUMERIC, 2) AS revenue
FROM read_parquet('/tmp/sales_partitioned/*/*.parquet', hive_partitioning=true)
WHERE category = 'Electronics'
GROUP BY category;
输出:
┌─────────────┬────────┬───────────────┐
│ category │ orders │ revenue │
├─────────────┼────────┼───────────────┤
│ Electronics │ 299836 │ 78097755.07 │
└─────────────┴────────┴───────────────┘
DuckDB 只读取 category=Electronics/ 这一个子目录里的文件,跳过其余 4 个分区。数据量越大,分区裁剪的收益越明显——10 亿行数据分 30 个日分区,查询某一天只需扫描 1/30 的数据。

图:全表扫描需读取全部文件(左),分区裁剪只读取匹配的分区(右),跳过 80% 无关数据
分区优化的最佳实践
| 建议 | 说明 |
|---|---|
| 选择基数适中的列 | 分区列的值不宜太多也不宜太少。category(5 种)不错,status(3 种)也行 |
| 日期分区利器 | 按 date 或 month 分区是最高频场景——报表通常按时间范围查询 |
| 避免小文件 | 每个分区内至少几十 MB,否则分区管理的开销会抵消收益 |
用 hive_partitioning=true | 告诉 DuckDB 识别 key=value/ 目录格式 |
七、综合调优清单
把四项技巧结合起来,一个生产级的 DuckDB 调优模板如下:
-- ── DuckDB 生产调优模板 ──
-- 1. 内存限制:预留 20% 给 OS
SET memory_limit = '80%';
-- 2. 并行度:独占服务器用满全部核心
SET threads = 8;
-- 3. 临时目录:指向 SSD
SET temp_directory = '/mnt/ssd/duckdb_temp';
-- 4. 启用进度条(长查询友好)
SET enable_progress_bar = true;
-- 5. 不使用严格插入顺序(加速聚合)
SET preserve_insertion_order = false;
-- 6. 查询分区数据,利用分区裁剪
SELECT category, SUM(amount) AS total
FROM read_parquet('/data/sales/*/*.parquet', hive_partitioning=true)
WHERE category IN ('Electronics', 'Books')
GROUP BY category;
性能对照表(基于百万行测试数据)
| 配置 | 查询耗时 | 峰值内存 |
|---|---|---|
| 默认(2 线程, 2.9GB) | 0.08s | ~300MB |
| 受限(1 线程, 128MB) | 0.20s | ~128MB |
| 调优(8 线程, 8GB) | 0.05s | ~500MB |
| 分区裁剪(跳过 80% 数据) | 0.02s | ~60MB |
数据来源:1,000,000 行销售数据,Parquet 格式,子查询 JOIN 聚合查询。
八、总结
DuckDB 的调优核心思路只有一句话:给它刚刚好够用的资源,而不是越多越好。
memory_limit防 OOM,不是越大越快threads发挥多核优势,但太多反而降速temp_directory给内存兜底,RAID 0 SSD 更佳PARTITION BY减少数据扫描,10 倍性能提升不是梦
把这些配置写进你的 DuckDB 初始化脚本,或者 .duckdbrc 文件,一劳永逸。
更多 DuckDB 实战技巧,请关注 Olap Studio(duckdblab.org)