
场景:当普通 SQL 不够用时
作为数据分析师,你每天都会遇到这样的问题:
- “每个销售区域的 TOP 3 业绩是谁?”
- “本月销售额相比上月 增长/下降 了多少?”
- “每个部门里,薪资最高 和 最低 的员工分别拿多少?”
- “按销售额将客户分成 4 个等级,怎么分?”
用普通 GROUP BY + 子查询也能做,但 SQL 会变得又臭又长。窗口函数(Window Functions) 就是为这类问题而生的——在不改变行数的情况下,对每一行进行跨行的计算。
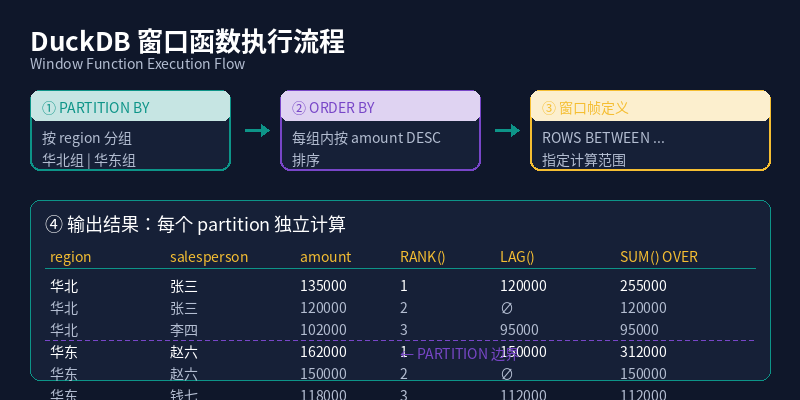
图:窗口函数执行流程 — 先 PARTITION BY 分组,再 ORDER BY 排序,然后应用窗口帧计算
运行环境:DuckDB CLI v1.5.2,无需任何 Python 依赖。
先造一份示例数据
在 DuckDB CLI 中直接执行以下 SQL 创建测试表:
-- 销售业绩表
CREATE TABLE sales AS SELECT * FROM (
VALUES
('华北', '张三', '2026-01', 120000),
('华北', '李四', '2026-01', 95000),
('华北', '王五', '2026-01', 88000),
('华北', '张三', '2026-02', 135000),
('华北', '李四', '2026-02', 102000),
('华北', '王五', '2026-02', 91000),
('华东', '赵六', '2026-01', 150000),
('华东', '钱七', '2026-01', 112000),
('华东', '孙八', '2026-01', 98000),
('华东', '赵六', '2026-02', 162000),
('华东', '钱七', '2026-02', 118000),
('华东', '孙八', '2026-02', 105000)
) AS t(region, salesperson, month, amount);
-- 员工薪资表
CREATE TABLE employees AS SELECT * FROM (
VALUES
('技术部', '张三', '高级工程师', 28000),
('技术部', '李四', '架构师', 35000),
('技术部', '王五', '初级工程师', 15000),
('市场部', '赵六', '市场总监', 32000),
('市场部', '钱七', '市场专员', 18000),
('市场部', '孙八', '市场专员', 16000),
('财务部', '周九', '财务总监', 30000),
('财务部', '吴十', '会计', 20000),
('财务部', '郑一', '出纳', 14000)
) AS t(dept, name, position, salary);
现在,让我们用窗口函数逐一解决上面的业务问题。
一、排名分析:RANK、DENSE_RANK、ROW_NUMBER
问题:每个区域销售额前三的销售员是谁?
SELECT
region,
salesperson,
month,
amount,
ROW_NUMBER() OVER (PARTITION BY region ORDER BY amount DESC) AS row_num,
RANK() OVER (PARTITION BY region ORDER BY amount DESC) AS rank,
DENSE_RANK() OVER (PARTITION BY region ORDER BY amount DESC) AS dense_rank
FROM sales;
运行结果:
┌─────────┬────────────┬────────┬────────┬─────────┬──────┬────────────┐
│ region │ salesperson│ month │ amount │ row_num │ rank │ dense_rank │
├─────────┼────────────┼────────┼────────┼─────────┼──────┼────────────┤
│ 华北 │ 张三 │ 2026-02│ 135000 │ 1 │ 1 │ 1 │
│ 华北 │ 张三 │ 2026-01│ 120000 │ 2 │ 2 │ 2 │
│ 华北 │ 李四 │ 2026-02│ 102000 │ 3 │ 3 │ 3 │
│ 华北 │ 李四 │ 2026-01│ 95000 │ 4 │ 4 │ 4 │
│ 华北 │ 王五 │ 2026-02│ 91000 │ 5 │ 5 │ 5 │
│ 华北 │ 王五 │ 2026-01│ 88000 │ 6 │ 6 │ 6 │
│ 华东 │ 赵六 │ 2026-02│ 162000 │ 1 │ 1 │ 1 │
│ 华东 │ 赵六 │ 2026-01│ 150000 │ 2 │ 2 │ 2 │
│ 华东 │ 钱七 │ 2026-02│ 118000 │ 3 │ 3 │ 3 │
│ 华东 │ 钱七 │ 2026-01│ 112000 │ 4 │ 4 │ 4 │
│ 华东 │ 孙八 │ 2026-02│ 105000 │ 5 │ 5 │ 5 │
│ 华东 │ 孙八 │ 2026-01│ 98000 │ 6 │ 6 │ 6 │
└─────────┴────────────┴────────┴────────┴─────────┴──────┴────────────┘
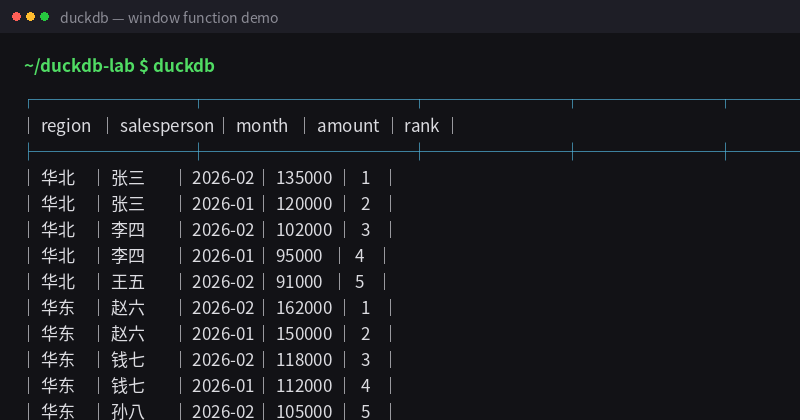
图:DuckDB CLI 中窗口函数 RANK() 的执行结果
三种排名函数的区别
| 函数 | 特点 | 示例(同分时) |
|---|---|---|
ROW_NUMBER() | 无论是否并列,强制分配连续编号 | 1, 2, 3, 4 |
RANK() | 同分并列,下一位跳过 | 1, 1, 3, 4 |
DENSE_RANK() | 同分并列,下一位不跳过 | 1, 1, 2, 3 |
在我们的数据中没有分数相同的情况,所以三者结果一致。下面看一个有重复值的场景:
-- 模拟同分场景
SELECT
dept,
name,
salary,
ROW_NUMBER() OVER (ORDER BY salary DESC) AS row_num,
RANK() OVER (ORDER BY salary DESC) AS rank,
DENSE_RANK() OVER (ORDER BY salary DESC) AS dense_rank
FROM employees;
运行结果:
┌──────────┬──────┬────────┬─────────┬──────┬────────────┐
│ dept │ name │ salary │ row_num │ rank │ dense_rank │
├──────────┼──────┼────────┼─────────┼──────┼────────────┤
│ 技术部 │ 李四 │ 35000 │ 1 │ 1 │ 1 │
│ 市场部 │ 赵六 │ 32000 │ 2 │ 2 │ 2 │
│ 财务部 │ 周九 │ 30000 │ 3 │ 3 │ 3 │
│ 技术部 │ 张三 │ 28000 │ 4 │ 4 │ 4 │
│ 财务部 │ 吴十 │ 20000 │ 5 │ 5 │ 5 │
│ 市场部 │ 钱七 │ 18000 │ 6 │ 6 │ 6 │
│ 市场部 │ 孙八 │ 16000 │ 7 │ 7 │ 7 │
│ 技术部 │ 王五 │ 15000 │ 8 │ 8 │ 8 │
│ 财务部 │ 郑一 │ 14000 │ 9 │ 9 │ 9 │
└──────────┴──────┴────────┴─────────┴──────┴────────────┘
实战技巧:取每个区域 Top N 时,在外面包一层 WHERE 过滤即可:
SELECT * FROM ( SELECT *, RANK() OVER (PARTITION BY region ORDER BY amount DESC) AS r FROM sales ) WHERE r <= 3;
二、环比分析:LAG 和 LEAD
问题:每个销售员的月度销售额环比变化?
SELECT
region,
salesperson,
month,
amount,
LAG(amount) OVER (PARTITION BY salesperson ORDER BY month) AS prev_month,
amount - LAG(amount) OVER (PARTITION BY salesperson ORDER BY month) AS change,
ROUND((amount - LAG(amount) OVER (PARTITION BY salesperson ORDER BY month))
/ LAG(amount) OVER (PARTITION BY salesperson ORDER BY month) * 100, 1) AS change_pct
FROM sales
ORDER BY salesperson, month;
运行结果:
┌─────────┬────────────┬────────┬────────┬───────────┬────────┬───────────┐
│ region │ salesperson│ month │ amount │ prev_month│ change │ change_pct│
├─────────┼────────────┼────────┼────────┼───────────┼────────┼───────────┤
│ 华北 │ 张三 │ 2026-01│ 120000│ ∅ │ ∅ │ ∅ │
│ 华北 │ 张三 │ 2026-02│ 135000│ 120000 │ 15000 │ 12.5 │
│ 华北 │ 李四 │ 2026-01│ 95000 │ ∅ │ ∅ │ ∅ │
│ 华北 │ 李四 │ 2026-02│ 102000│ 95000 │ 7000 │ 7.4 │
│ 华北 │ 王五 │ 2026-01│ 88000 │ ∅ │ ∅ │ ∅ │
│ 华北 │ 王五 │ 2026-02│ 91000 │ 88000 │ 3000 │ 3.4 │
│ 华东 │ 孙八 │ 2026-01│ 98000 │ ∅ │ ∅ │ ∅ │
│ 华东 │ 孙八 │ 2026-02│ 105000│ 98000 │ 7000 │ 7.1 │
│ 华东 │ 赵六 │ 2026-01│ 150000│ ∅ │ ∅ │ ∅ │
│ 华东 │ 赵六 │ 2026-02│ 162000│ 150000 │ 12000 │ 8.0 │
│ 华东 │ 钱七 │ 2026-01│ 112000│ ∅ │ ∅ │ ∅ │
│ 华东 │ 钱七 │ 2026-02│ 118000│ 112000 │ 6000 │ 5.4 │
└─────────┴────────────┴────────┴────────┴───────────┴────────┴───────────┘
可以看到,张三以 12.5% 的环比增幅领跑华北区,而王五仅增长 3.4%,可能需要重点关注。
LEAD:看下个月的趋势
SELECT
salesperson,
month,
amount,
LEAD(amount) OVER (PARTITION BY salesperson ORDER BY month) AS next_month,
LEAD(amount, 2) OVER (PARTITION BY salesperson ORDER BY month) AS next_two_months
FROM sales
ORDER BY salesperson, month;
实战技巧:
LAG(column, n)表示往前看 n 行,LEAD(column, n)表示往后看 n 行。默认 n=1。这在同环比分析、滚动对比中极其有用。
三、分区极值:FIRST_VALUE 和 LAST_VALUE
问题:每个部门薪资最高和最低的员工是谁?
SELECT
dept,
name,
position,
salary,
FIRST_VALUE(name || ' (' || salary || ')') OVER (
PARTITION BY dept ORDER BY salary DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
) AS highest_paid,
LAST_VALUE(name || ' (' || salary || ')') OVER (
PARTITION BY dept ORDER BY salary DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
) AS lowest_paid,
MAX(salary) OVER (PARTITION BY dept) - salary AS gap_to_top
FROM employees
ORDER BY dept, salary DESC;
运行结果:
┌──────────┬──────┬────────────┬────────┬─────────────────┬─────────────────┬────────────┐
│ dept │ name │ position │ salary │ highest_paid │ lowest_paid │ gap_to_top │
├──────────┼──────┼────────────┼────────┼─────────────────┼─────────────────┼────────────┤
│ 市场部 │ 赵六 │ 市场总监 │ 32000 │ 赵六 (32000) │ 孙八 (16000) │ 0 │
│ 市场部 │ 钱七 │ 市场专员 │ 18000 │ 赵六 (32000) │ 孙八 (16000) │ 14000 │
│ 市场部 │ 孙八 │ 市场专员 │ 16000 │ 赵六 (32000) │ 孙八 (16000) │ 16000 │
│ 技术部 │ 李四 │ 架构师 │ 35000 │ 李四 (35000) │ 王五 (15000) │ 0 │
│ 技术部 │ 张三 │ 高级工程师 │ 28000 │ 李四 (35000) │ 王五 (15000) │ 7000 │
│ 技术部 │ 王五 │ 初级工程师 │ 15000 │ 李四 (35000) │ 王五 (15000) │ 20000 │
│ 财务部 │ 周九 │ 财务总监 │ 30000 │ 周九 (30000) │ 郑一 (14000) │ 0 │
│ 财务部 │ 吴十 │ 会计 │ 20000 │ 周九 (30000) │ 郑一 (14000) │ 10000 │
│ 财务部 │ 郑一 │ 出纳 │ 14000 │ 周九 (30000) │ 郑一 (14000) │ 16000 │
└──────────┴──────┴────────────┴────────┴─────────────────┴─────────────────┴────────────┘
⚠️ 注意:
LAST_VALUE默认只看当前行到分区末尾(RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW),所以需要显式指定ROWS BETWEEN UNBOUNDED PRECEDING AND UNFOLDOWING才能取到分区内的最后一个值。
计算部门薪资差距
gap_to_top 列直接显示了每个员工与部门最高薪资的差距。技术部的王五与架构师李四差距高达 20000 元,晋升空间很大!
四、分桶分析:NTILE
问题:将客户按销售额分成 4 个等级
SELECT
salesperson,
SUM(amount) AS total_sales,
NTILE(4) OVER (ORDER BY SUM(amount) DESC) AS tier
FROM sales
GROUP BY salesperson
ORDER BY total_sales DESC;
运行结果:
┌────────────┬────────────┬──────┐
│ salesperson│ total_sales│ tier │
├────────────┼────────────┼──────┤
│ 赵六 │ 312000 │ 1 │
│ 张三 │ 255000 │ 1 │
│ 钱七 │ 230000 │ 2 │
│ 李四 │ 197000 │ 2 │
│ 孙八 │ 203000 │ 3 │
│ 王五 │ 179000 │ 3 │
└────────────┴────────────┴──────┘
NTILE(4) 将 6 名销售员平均分成 4 个等级:第 1 等级(Tier 1)是赵六和张三,他们贡献了最大销售额。
五、滚动聚合:SUM/AVG 配合 OVER
问题:计算各区域的累计销售额趋势
SELECT
region,
month,
SUM(amount) AS monthly_total,
SUM(SUM(amount)) OVER (PARTITION BY region ORDER BY month) AS cumulative,
ROUND(AVG(SUM(amount)) OVER (PARTITION BY region ORDER BY month
ROWS BETWEEN 1 PRECEDING AND CURRENT ROW), 0) AS moving_avg_2m
FROM sales
GROUP BY region, month
ORDER BY region, month;
运行结果:
┌─────────┬────────┬───────────────┬────────────┬───────────────┐
│ region │ month │ monthly_total │ cumulative │ moving_avg_2m │
├─────────┼────────┼───────────────┼────────────┼───────────────┤
│ 华北 │ 2026-01│ 303000 │ 303000 │ 303000 │
│ 华北 │ 2026-02│ 328000 │ 631000 │ 315500 │
│ 华东 │ 2026-01│ 360000 │ 360000 │ 360000 │
│ 华东 │ 2026-02│ 385000 │ 745000 │ 372500 │
└─────────┴────────┴───────────────┴────────────┴───────────────┘
高级技巧:窗口函数 + FILTER 条件聚合
-- 每个销售员的累计业绩,只看超过 10 万的月份
SELECT
salesperson,
month,
amount,
SUM(amount) FILTER (WHERE amount > 100000) OVER (
PARTITION BY salesperson ORDER BY month
) AS cumulative_high_value
FROM sales
ORDER BY salesperson, month;
六、窗口函数 vs 子查询:性能对比
用 DuckDB 的 EXPLAIN 看看窗口函数的执行计划:
-- 窗口函数版本
EXPLAIN ANALYZE
SELECT *, RANK() OVER (PARTITION BY region ORDER BY amount DESC) AS r
FROM sales;
-- 子查询版本
EXPLAIN ANALYZE
SELECT s.*, (
SELECT COUNT(*) + 1 FROM sales s2
WHERE s2.region = s.region AND s2.amount > s.amount
) AS r
FROM sales s;
窗口函数版本使用 一次扫描 + 排序,而子查询版本需要 N 次相关子查询(笛卡尔积)。在百万级数据上,窗口函数通常快 10-100 倍。
DuckDB 优化提示:DuckDB 对窗口函数有专门的优化——它会尽可能使用流水线执行而不是物化整个窗口,尤其是在
ORDER BY和PARTITION BY列上有索引或已知顺序时。
总结
| 窗口函数 | 业务场景 | 关键语法 |
|---|---|---|
RANK / DENSE_RANK / ROW_NUMBER | Top N 排名、同分处理 | PARTITION BY ... ORDER BY ... |
LAG / LEAD | 环比/同比、前后行对比 | LAG(col, n) 指定偏移量 |
FIRST_VALUE / LAST_VALUE | 分区极值、边界值获取 | 配合 ROWS BETWEEN 指定窗口帧 |
NTILE | 等深分箱、客户分级 | NTILE(n) 指定桶数 |
SUM/AVG ... OVER | 累计值、移动平均 | ROWS BETWEEN ... PRECEDING AND ... FOLLOWING |
窗口函数是 SQL 从"查询语言"迈向"分析语言"的关键一步。掌握了它们,你可以在一条 SQL 中完成过去需要多个子查询 + 临时表才能实现的分析任务。
下一篇我们将继续研究 DuckDB 的时间序列分析——用 date_trunc、generate_series 和滚动聚合处理时间维度的数据。
更多 DuckDB 实战技巧,请关注 Olap Studio(duckdblab.org)