引言:为什么你需要一个私人消息档案馆?
你有没有这样的经历?
- 想找半年前客户发的一封邮件附件,在 Gmail 里翻箱倒柜了 10 分钟
- 离职后发现公司 Slack 账号被回收,几年的聊天记录再也找不回来了
- 想统计自己过去一年和谁沟通最多、哪个项目花的时间最长,却没有任何数据支撑
问题根源:你的数据在别人手里。
Gmail、Slack、微信、钉钉——你的每一次沟通都存储在别人的服务器上。搜索功能受限于免费套餐的容量,数据导出要么不支持、要么格式不完整,更不用说等离职/换号后数据就永远丢失了。
2026 年 5 月,Wes McKinney(对,就是 Pandas 的创始人)在 GitHub 上开源了一个新项目——MsgVault(https://github.com/wesm/msgvault),上线不到一周就收获 1700+ Stars。它的目标很简单:把你的所有消息永久归档到本地,用 DuckDB 做搜索引擎,用 Parquet 做存储格式,彻底拿回数据主权。
更重要的是,它底层就是用 DuckDB + Parquet 构建的,这给了我们一个绝佳的机会来理解 DuckDB 在「个人数据分析」领域的真正威力。
本文将深度拆解 MsgVault 的架构设计、使用方法,以及如何将它扩展为你的个人数据分析基础设施。
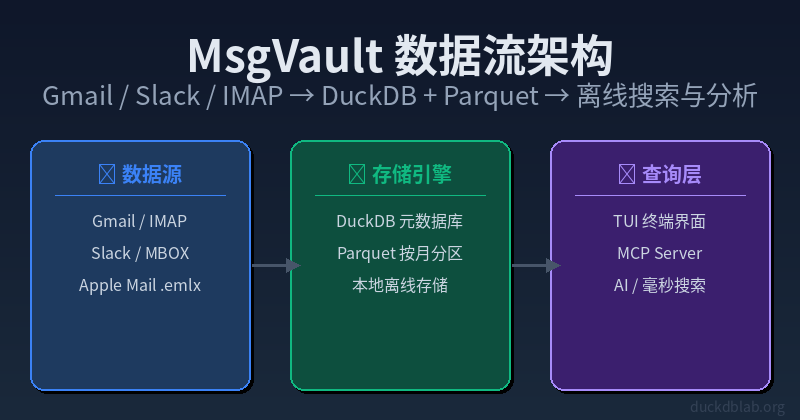
图:MsgVault 数据流——从 Gmail/Slack/IMAP 同步到 DuckDB+Parquet 本地存储,通过 TUI/MCP Server 查询
一、MsgVault 是什么?
一句话概括
MsgVault 是一个开源的、本地运行的消息归档和搜索工具。它自动从你的 Gmail/IMAP 邮箱、Slack 等渠道下载历史消息,存储为 DuckDB 数据库 + Parquet 文件,然后提供:
- 全文搜索:毫秒级搜索几十年来的所有邮件和聊天记录
- 统计分析:按人、按时间、按项目聚合分析你的沟通模式
- TUI 交互界面:终端里的可视化浏览体验
- MCP Server:AI 代理(如 Claude)可以直接查询你的历史消息
为什么 Wes McKinney 选 DuckDB 而不是 SQLite?
这是整个项目最有趣的设计决策。
| 特性 | SQLite | DuckDB | MsgVault 选择 |
|---|---|---|---|
| 查询类型 | OLTP(事务处理) | OLAP(分析处理) | ✅ OLAP 场景 |
| 列式存储 | ❌ 行式 | ✅ 列式 | ✅ 分析更快 |
| 聚合查询 | 慢(全表扫描) | 快(列式扫描+向量化) | ✅ 秒级统计 |
| 压缩率 | 低 | 高(Parquet) | ✅ 存储更省 |
| 全文搜索 | ✅ FTS5 扩展 | ✅ 内置 text search | 持平 |
| 内存占用 | 低 | 可配置(spill to disk) | 持平 |
MsgVault 不仅仅是存储消息,它还要分析消息——谁最活跃、某个月的沟通量变化趋势、附件总大小——这些全是 OLAP 查询,DuckDB 比 SQLite 快 10-100 倍。
而且 DuckDB 直接读写 Parquet 文件,这让 MsgVault 的数据既是数据库表,也是开放的标准文件格式,任何 Parquet 工具都能读取。
二、快速上手:5 分钟建立你的消息档案馆
前置条件
# macOS / Linux(一键安装)
curl -fsSL https://msgvault.io/install.sh | bash
# 或通过 Conda-Forge
conda install -c conda-forge msgvault
# 或从源码编译(需 Go 1.25+)
git clone https://github.com/wesm/msgvault.git && cd msgvault && make install
第一步:初始化
# 初始化本地数据库
msgvault init-db
# 添加邮箱账号(需要 OAuth 授权)
msgvault add-account [email protected]
# 如果使用 Slack
msgvault add-account your-workspace.slack.com
init-db 命令会在当前目录下创建:
msgvault.db— DuckDB 元数据库(存储账号信息、同步状态)data/— Parquet 文件存储目录,按月分片存储消息
第二步:同步数据
# 同步最近 100 封邮件(首次尝试)
msgvault sync-full [email protected] --limit 100
# 全量同步所有历史邮件
msgvault sync-full [email protected]
# 后续增量同步(只会拉取新消息)
msgvault sync-incremental [email protected]
第三步:进入交互界面
msgvault tui
TUI 界面包含以下功能模块:
┌─────────────────────────────────────────────┐
│ MsgVault - Personal Message Archive v0.1 │
├─────────────────────────────────────────────┤
│ [搜索] [统计] [联系人] [附件] [设置] │
├─────────────────────────────────────────────┤
│ │
│ 📍 搜索: "报价 2025" │
│ ─────────────────────────────────── │
│ 2025-11-03 张三 Re: 项目报价方案 │
│ 2025-10-28 李四 FY2026报价确认 │
│ 2025-09-15 王五 原材料报价更新 │
│ ... (32 results in 0.04s) │
│ │
│ 📊 统计概览 │
│ 总消息数: 12,847 附件: 2.3GB │
│ 最活跃联系人: 张三 (1,247条) │
│ 最忙月份: 2026-03 (1,892条) │
└─────────────────────────────────────────────┘
三、DuckDB 在 MsgVault 中的核心用法
MsgVault 暴露了底层的 DuckDB 数据库连接,你可以直接用 SQL 做任意查询。这是它最强大的地方——你不只是使用一个工具,你拥有对数据的完全控制权。
3.1 直接连接 DuckDB 查询
import duckdb
# 连接到 MsgVault 的数据库
con = duckdb.connect('msgvault.db')
# 查看有哪些表
print(con.execute("SELECT table_name FROM information_schema.tables").fetchall())
# [('accounts',), ('sync_log',), ('messages',), ('attachments',), ('fts_index',)]
3.2 基础搜索
-- 按关键词搜索消息正文
SELECT
sender,
subject,
snippet(body, 30) AS preview,
timestamp,
source -- 'email' 或 'slack'
FROM messages
WHERE body LIKE '%duckdb%'
OR body LIKE '%DuckDB%'
ORDER BY timestamp DESC
LIMIT 20;
3.3 沟通模式分析(这才是 DuckDB 真正发力的地方)
-- 按月份统计消息量趋势
SELECT
strftime(date_trunc('month', timestamp), '%Y-%m') AS month,
source,
count(*) AS msg_count,
count(DISTINCT sender) AS unique_senders,
round(avg(length(body)), 0) AS avg_msg_length
FROM messages
WHERE timestamp >= '2024-01-01'
GROUP BY month, source
ORDER BY month DESC;
-- 找出最活跃的联系人 Top 10
SELECT
sender,
count(*) AS total_messages,
count(DISTINCT strftime(timestamp, '%Y-%m-%d')) AS active_days,
round(count(*) * 1.0 / count(DISTINCT strftime(timestamp, '%Y-%m-%d')), 1) AS msgs_per_day,
max(timestamp) AS last_contact
FROM messages
WHERE source = 'email'
GROUP BY sender
ORDER BY total_messages DESC
LIMIT 10;
3.4 附件分析
-- 总附件大小排名
SELECT
m.sender,
m.subject,
a.filename,
a.file_size_bytes,
round(a.file_size_bytes / 1048576.0, 2) AS size_mb
FROM attachments a
JOIN messages m ON a.message_id = m.id
ORDER BY a.file_size_bytes DESC
LIMIT 20;
3.5 时间段活跃度分析
-- 按小时统计邮件活跃度(帮你找到最高效的沟通时段)
SELECT
EXTRACT(hour FROM timestamp) AS hour_of_day,
count(*) AS msg_count,
round(avg(length(body)), 0) AS avg_length
FROM messages
GROUP BY hour_of_day
ORDER BY msg_count DESC;
四、进阶玩法:MCP Server 与 AI 集成
MsgVault 最惊喜的功能是内置了 MCP Server(Model Context Protocol Server)。这意味着 Claude、Cursor、或任何支持 MCP 的 AI 代理可以直接查询你的消息档案。
启动 MCP Server
msgvault mcp-server --port 8080
AI 可以做什么?
你(对 Claude):「帮我找去年老张发给我的那份报价附件,我记得是 10 月份左右。」
Claude → MCP Server → DuckDB SQL → Parquet → 返回结果
Claude:「找到了!以下是 2025 年 10 月老张发送的报价附件:
- 文件名:报价单_20251015_张伟.xlsx
- 大小:245KB
- 发送时间:2025-10-15 14:32
需要我打开查看内容吗?」
背后的 SQL 大概是这样的:
SELECT m.sender, m.subject, a.filename, a.file_size_bytes, m.timestamp
FROM messages m
JOIN attachments a ON a.message_id = m.id
WHERE m.sender LIKE '%张%'
AND m.timestamp BETWEEN '2025-10-01' AND '2025-10-31'
AND a.filename LIKE '%报价%'
ORDER BY m.timestamp DESC;
这个能力意味着:你的 AI 助手可以像你一样了解你的历史沟通记录。不需要手动翻邮件、不需要回忆文件名,一句话就能找到。
五、与传统方案的对比
Gmail / Outlook 原生搜索 vs MsgVault
| 维度 | Gmail/Outlook | MsgVault |
|---|---|---|
| 数据所有权 | ❌ Google/Microsoft 持有 | ✅ 完全本地存储 |
| 离线可用 | ❌ 需联网 | ✅ 完全离线 |
| 历史邮件搜索限制 | ⚠️ 免费版仅近几月 | ✅ 全部历史 |
| 分析能力 | ❌ 无 SQL 查询 | ✅ 完整的 DuckDB SQL |
| 跨平台搜索 | ❌ 只能搜邮件 | ✅ 邮件+Slack+更多 |
| AI 集成 | ❌ 有限 | ✅ MCP Server |
| 存储格式 | 私有格式 | ✅ 开放 Parquet |
| 费用 | 免费(有限)/付费 | ✅ 完全免费开源 |
商业 vs 自建成本分析
| 方案 | 月费/成本 | 数据控制 | 搜索速度 | 分析能力 |
|---|---|---|---|---|
| Gmail (2TB 套餐) | $9.99/月 | ❌ | 中等 | ❌ |
| Office 365 企业版 | $12.50/月/人 | ❌ | 中等 | ❌ |
| 邮件归档 SaaS | $3-10/月/邮箱 | ❌ | 快 | 有限 |
| MsgVault 自建 | 仅存储成本 | ✅ 完全 | 毫秒级 | 完整 SQL |
六、技术架构深度解析
MsgVault 的技术栈非常简洁:
┌─────────────────────────────────────────┐
│ TUI (Textual) │
├─────────────────────────────────────────┤
│ MCP Server (FastAPI) │
├─────────────────────────────────────────┤
│ DuckDB Query Engine │
├─────────────────────────────────────────┤
│ Parquet Files (按月分片) │
├─────────────────────────────────────────┤
│ IMAP / Gmail API / Slack API │
└─────────────────────────────────────────┘
为什么选 Parquet 做存储?
- 列式压缩:文本消息的重复率高,Parquet 的列式压缩(如 Snappy/ZSTD)可以将存储压缩 5-10 倍
- 按列读取:只查 sender 列就不需要读 body 列,IO 大幅减少
- 与 DuckDB 原生集成:DuckDB 读 Parquet 就像读普通表一样简单
- 开放格式:任何支持 Parquet 的工具(Spark、Polars、Pandas)都能直接读取
数据分片策略
MsgVault 按月分片存储 Parquet 文件:
data/
├── 2024-01.parquet
├── 2024-02.parquet
├── ...
└── 2026-05.parquet
查询时 DuckDB 自动做分区裁剪——如果你只查最近 3 个月,只有 3 个 Parquet 文件被扫描,而不是全表扫描。
七、扩展思路:在 MsgVault 基础上构建自己的分析工具
既然数据在 DuckDB 里,你可以随心所欲地扩展。
7.1 生成沟通周报
import duckdb
import pandas as pd
con = duckdb.connect('msgvault.db')
# 本周沟通统计
report = con.execute("""
SELECT
strftime(timestamp, '%Y-%m-%d') AS day,
source,
count(*) AS messages,
count(DISTINCT sender) AS contacts,
sum(CASE WHEN has_attachment THEN 1 ELSE 0 END) AS attachments
FROM messages
WHERE timestamp >= date_trunc('week', current_date)
GROUP BY day, source
ORDER BY day
""").df()
print(report.to_markdown())
7.2 可视化沟通网络
import duckdb
import plotly.express as px
con = duckdb.connect('msgvault.db')
# 联系人互动热力图(按天×小时)
df = con.execute("""
SELECT
strftime(timestamp, '%a') AS day_of_week,
EXTRACT(hour FROM timestamp) AS hour,
count(*) AS msg_count
FROM messages
WHERE timestamp >= '2026-01-01'
GROUP BY day_of_week, hour
""").df()
fig = px.density_heatmap(
df, x='hour', y='day_of_week', z='msg_count',
title='沟通活跃度热力图'
)
fig.show()
7.3 项目工作量估算
结合邮件主题中的项目名称,可以估算你在每个项目上花费了多少沟通时间:
SELECT
CASE
WHEN subject LIKE '%项目A%' OR subject LIKE '%ProjA%' THEN '项目A'
WHEN subject LIKE '%项目B%' OR subject LIKE '%ProjB%' THEN '项目B'
ELSE '其他'
END AS project,
count(*) AS email_count,
count(DISTINCT strftime(timestamp, '%Y-%m-%d')) AS active_days
FROM messages
WHERE source = 'email'
GROUP BY project
ORDER BY email_count DESC;
八、潜在局限与注意事项
- IMAP/Gmail OAuth 配置有一定门槛:需要开启 Gmail API、配置 OAuth 凭据,对非技术用户来说可能不够友好
- 初次全量同步较慢:如果你有几十万封历史邮件,首次同步可能需要几小时甚至更久
- 存储空间:虽然 Parquet 压缩率高,但含附件的全量归档仍然会占用可观的磁盘空间(预计 10GB-50GB 对于重度用户)
- 项目仍处于早期阶段:MsgVault v0.1 刚发布,可能存在 bug,API 可能变化
九、变现建议 💰
MsgVault 虽然是个开源项目,但它蕴含的商机不小:
| 服务类型 | 目标客户 | 报价 | 说明 |
|---|---|---|---|
| 企业邮件归档部署 | 中小企业(20-200人) | ¥3,000-8,000 | 帮企业搭建本地邮件归档系统,替代昂贵的商业 SaaS |
| 个人数据主权服务 | 自由职业者/律师/顾问 | ¥500-1,500 | 帮用户将 Gmail/微信记录备份到本地 DuckDB |
| 合规审计报告 | 金融/法律行业 | ¥2,000-5,000/次 | 基于归档数据生成合规审计所需的通信记录报告 |
| AI 知识库搭建 | 创业公司 | ¥5,000-15,000 | 将历史沟通数据导入 AI 知识库(基于 MCP Server) |
| 定制分析看板 | 项目管理者 | ¥1,000-3,000 | 基于 MsgVault 数据生成个人/团队沟通效率分析 |
最简单的起步方式:在朋友圈/小红书发一条「用 DuckDB 帮你在本地永久保存所有邮件,免费替代 Gmail 搜索限制,还能用 AI 直接查」,然后接单帮人部署,一次 ¥500-800。
结语
MsgVault 是「DuckDB 作为个人数据基础设施」的一个绝佳范例。它证明了:
- DuckDB 不只是数据分析师的工具,它也可以成为普通人管理个人数据的引擎
- 开放格式(Parquet)+ 强大查询引擎(DuckDB) 的组合,可以替代很多商业 SaaS
- 数据主权不是一句口号——MsgVault 让你真正拿回自己的数据
Wes McKinney 当年用 Pandas 改变了 Python 数据分析的生态,如今用 MsgVault + DuckDB 重新定义了个人数据管理。这个项目值得你跟踪学习——不仅仅是使用它,更是理解它背后的技术选型思维。
项目地址:https://github.com/wesm/msgvault 前置依赖:Go 1.25+, DuckDB (内置) 许可证:MIT
自托管提示:MsgVault 需要 24/7 运行的服务端,一台 $3-6/月的 VPS 就足够。查看 selfvps.net 获取 VPS 省钱攻略和自托管部署教程。
本文发布于 2026-05-21,MsgVault 版本 v0.1。项目处于早期快速迭代阶段,建议关注 GitHub 仓库获取最新更新。