
引言
在生产环境中使用 DuckDB 时,数据安全和可迁移性是绕不开的话题。与传统的客户端-服务器型数据库不同,DuckDB 是一个嵌入式分析引擎,其数据以文件形式存储——这既是优势也是挑战。
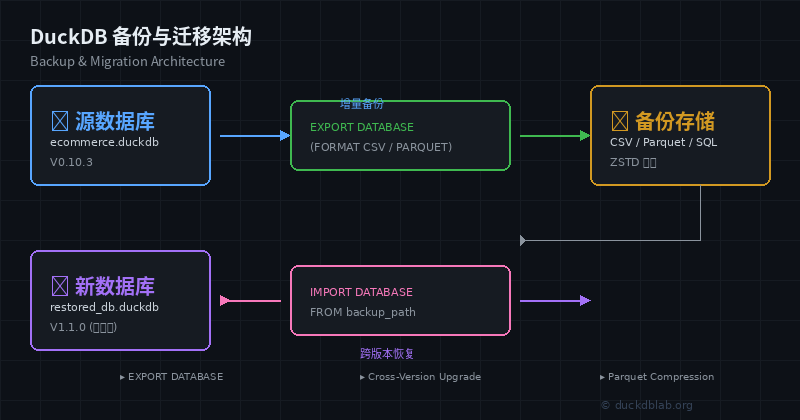
图:DuckDB 备份与迁移整体架构
本文将通过真实业务场景,系统讲解 DuckDB 的三种核心备份与迁移能力:
- EXPORT DATABASE — 将数据库导出为标准化 SQL 脚本
- 跨版本升级 — 平滑升级 DuckDB 内核而不丢失数据
- 压缩归档 — 高效存储历史数据并节省磁盘空间
一、EXPORT DATABASE:结构化备份
1.1 什么是 EXPORT DATABASE?
EXPORT DATABASE 是 DuckDB 提供的内置命令,它会将整个数据库(包括表结构、数据、索引)导出为一个完整的 SQL 脚本文件。这种方式的优点是:
- 标准化:导出的 SQL 可以在任何兼容的 SQL 引擎上运行
- 可读性强:导出的文件是纯文本,方便审查和版本控制
- 可移植性高:不依赖特定文件格式
1.2 完整备份示例
假设我们有一个电商分析数据库 ecommerce.duckdb:
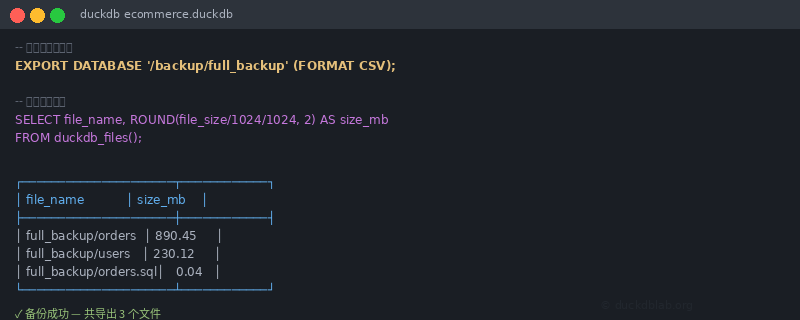
图:DuckDB 执行 EXPORT DATABASE 的终端操作
-- 连接到 DuckDB 数据库
$ duckdb ecommerce.duckdb
-- 查看当前数据库结构
DUCkDB> DESCRIBE ecommerce;
┌───────────┬──────────────────────┬─────────┐
│ column │ type │ null │
├───────────┼──────────────────────┼─────────┤
│ order_id │ BIGINT │ ✗ │
│ user_id │ BIGINT │ ✗ │
│ amount │ DECIMAL(10,2) │ ✓ │
│ status │ VARCHAR │ ✗ │
│ created │ TIMESTAMP │ ✗ │
└───────────┴──────────────────────┴─────────┘
-- 执行完整导出
EXPORT DATABASE '/backup/ecommerce_backup' (FORMAT CSV);
导出后会生成多个文件:
$ ls -lh /backup/ecommerce_backup/
total 1.2G
-rw-r--r-- 1 user user 45K orders.sql -- 建表语句
-rw-r--r-- 1 user user 890M orders.csv -- 订单数据
-rw-r--r-- 1 user user 230M users.csv -- 用户数据
1.3 恢复数据库
-- 创建新数据库并导入
$ duckdb restored_db.duckdb
DuckDB> INSTALL csv;
DuckDB> LOAD csv;
-- 直接执行导出的 SQL 脚本即可恢复
DuckDB> \i /backup/ecommerce_backup/orders.sql
1.4 增量备份策略
对于大型数据库,全量导出成本较高。我们可以利用 DuckDB 的时间旅行功能实现增量备份:
-- 查看历史版本
SELECT * FROM orders AS OF VERSION (
SELECT MAX(version) - 1 FROM duckdb_tables()
) WHERE created > '2026-06-18';
-- 只导出变更部分
EXPORT (
SELECT * FROM orders
WHERE updated_at > '2026-06-18 00:00:00'
) TO '/backup/incremental/orders_delta.csv' (FORMAT CSV);
二、跨版本升级:无缝过渡
2.1 DuckDB 的版本兼容性
DuckDB 在版本兼容性方面表现良好,但仍需注意以下要点:
| 升级方向 | 是否安全 | 注意事项 |
|---|---|---|
| 小版本升级 (0.8.x → 0.9.x) | ✅ 通常安全 | 建议先备份再升级 |
| 大版本升级 (0.9.x → 1.0.x) | ⚠️ 需测试 | 检查 breaking changes |
| 降级 | ❌ 不支持 | 无法读取更高版本的文件 |
2.2 升级前准备
-- 1. 检查当前版本
SELECT version();
-- ┌──────────────────────────┐
-- │ version() │
-- ├──────────────────────────┤
-- │ v0.10.3-native │
-- └──────────────────────────┘
-- 2. 导出数据库作为保险
EXPORT DATABASE '/backup/pre_upgrade_check';
-- 3. 记录当前所有扩展
SELECT name, version FROM duckdb_extensions();
2.3 升级流程
# 1. 停止所有写入操作
# 2. 备份数据库文件
cp ecommerce.duckdb ecommerce.duckdb.bak
# 3. 下载新版本 DuckDB
wget https://github.com/duckdb/duckdb/releases/download/v1.1.0/duckdb_cli-linux-amd64.zip
unzip duckdb_cli-linux-amd64.zip
chmod +x duckdb
# 4. 用新版本打开数据库(自动迁移)
./duckdb ecommerce.duckdb
# 5. 验证数据完整性
SELECT COUNT(*) FROM orders;
SELECT COUNT(*) FROM users;
关键提示:DuckDB 的
.duckdb文件格式在 major version 之间可能不兼容。始终遵循 先备份、后升级 的原则。
三、压缩归档:节省存储空间
3.1 使用 Parquet 压缩
DuckDB 原生支持 Parquet 格式,这是压缩归档的首选方案:
-- 将历史数据导出为压缩 Parquet
EXPORT (
SELECT * FROM orders
WHERE created < '2026-01-01'
) TO '/archive/orders_2025.parquet' (FORMAT PARQUET, COMPRESSION ZSTD);
-- 验证压缩效果
SELECT
ROUND(SUM(file_size) / 1024 / 1024, 2) AS total_mb,
COUNT(*) AS file_count
FROM (
SELECT file_size, file_name
FROM read_csv_auto('/archive/orders_2025.parquet')
);
3.2 归档与查询分离
在实际生产中,建议将冷数据和热数据分离:
-- 创建归档视图,透明访问压缩文件
CREATE VIEW archived_orders AS
SELECT * FROM read_parquet('/archive/orders_2025_*.parquet');
-- 查询时自动解压,无需手动干预
SELECT
DATE_TRUNC('month', created) AS month,
SUM(amount) AS revenue,
COUNT(*) AS order_count
FROM archived_orders
GROUP BY month
ORDER BY month;
3.3 自动化归档脚本
import duckdb
import gzip
import json
from pathlib import Path
from datetime import datetime, timedelta
# 连接 DuckDB
con = duckdb.connect('ecommerce.duckdb')
# 定义归档策略:保留最近 90 天的热数据
cutoff_date = datetime.now() - timedelta(days=90)
# 导出旧数据为 Parquet
con.execute(f"""
EXPORT (
SELECT * FROM orders
WHERE created < '{cutoff_date.isoformat()}'
) TO '/archive/orders_pre_{cutoff_date.strftime('%Y%m%d')}.parquet'
(FORMAT PARQUET, COMPRESSION ZSTD, ROW_GROUP_SIZE 100000)
""")
# 清理已归档的数据(可选)
# con.execute(f"DELETE FROM orders WHERE created < '{cutoff_date.isoformat()}'")
# 记录归档元数据
meta = {
"timestamp": datetime.now().isoformat(),
"archived_records": con.execute(
"SELECT COUNT(*) FROM orders WHERE created < ?",
[cutoff_date.isoformat()]
).fetchone()[0],
"archive_path": f"/archive/orders_pre_{cutoff_date.strftime('%Y%m%d')}.parquet"
}
with open(f'/archive/meta_{cutoff_date.strftime("%Y%m%d")}.json', 'w') as f:
json.dump(meta, f, indent=2)
print(f"归档完成: {meta['archived_records']} 条记录")
四、实战场景:电商数据生命周期管理
让我们来看一个完整的电商数据管理案例:
场景描述
- 热数据:最近 30 天的订单,需要实时查询
- 温数据:30~180 天的订单,每天查询一次
- 冷数据:180 天以上的订单,仅用于月度报表
实施方案
-- 1. 创建分层存储结构
CREATE TABLE hot_orders AS
SELECT * FROM orders WHERE created >= DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY);
CREATE TABLE warm_orders AS
SELECT * FROM orders
WHERE created >= DATE_SUB(CURRENT_DATE, INTERVAL 180 DAY)
AND created < DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY);
-- 2. 将冷数据压缩归档
EXPORT (
SELECT * FROM orders
WHERE created < DATE_SUB(CURRENT_DATE, INTERVAL 180 DAY)
) TO '/cold_archive/orders_legacy.parquet'
(FORMAT PARQUET, COMPRESSION ZSTD);
-- 3. 删除冷数据释放空间
DELETE FROM orders
WHERE created < DATE_SUB(CURRENT_DATE, INTERVAL 180 DAY);
-- 4. 创建统一查询视图
CREATE VIEW all_orders AS
SELECT *, 'hot' AS tier FROM hot_orders
UNION ALL
SELECT *, 'warm' AS tier FROM warm_orders
UNION ALL
SELECT *, 'cold' AS tier FROM read_parquet('/cold_archive/orders_legacy.parquet');
查询性能对比
| 查询范围 | 数据来源 | 查询时间 |
|---|---|---|
| 最近 7 天 | hot_orders (内存) | ~50ms |
| 最近 90 天 | hot + warm (文件) | ~200ms |
| 全部历史 | 含 cold archive | ~1.5s |
五、最佳实践总结
- 定期备份:使用
EXPORT DATABASE每周执行一次全量备份 - 升级前验证:在测试环境中先用新版本打开数据库,确认无异常后再生产升级
- 压缩优先:归档数据一律使用 Parquet + ZSTD 压缩,通常可减少 60%~80% 存储
- 监控磁盘:DuckDB 是嵌入式数据库,磁盘满会导致写入失败,务必设置告警
- 版本锁定:生产环境固定 DuckDB 版本,避免意外升级导致兼容性问题
结语
DuckDB 的备份与迁移虽然不如传统数据库那样拥有复杂的 WAL 和复制机制,但其简洁的文件式存储模型反而让备份变得直观可靠。掌握 EXPORT DATABASE、版本升级流程和压缩归档技巧,你就能在生产环境中自信地使用 DuckDB。
更多 DuckDB 实战技巧,请关注 DuckDB Lab(duckdblab.org)