引言
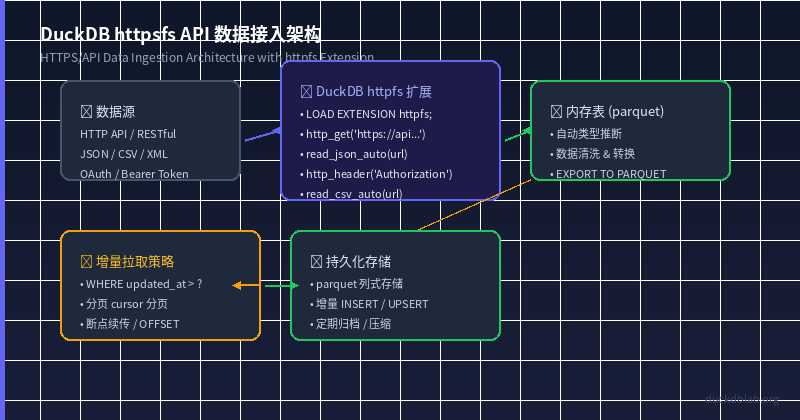
图:DuckDB httpfs API 数据接入架构
在数据分析的日常工作中,我们经常需要从外部 API 获取数据——无论是第三方服务的 RESTful API、内部微服务接口,还是公开的数据源(如 GitHub API、天气 API 等)。传统方案通常需要编写 Python 脚本调用 requests 库,将数据保存到本地文件后再导入数据库。这个过程涉及多个步骤、多个工具,而且容易出错。
DuckDB 的 httpfs 扩展让我们可以直接在 SQL 中读取远程 HTTPS 资源,将原本需要多步完成的数据接入流程简化为一条 SQL 语句。本文将通过一个电商销售数据 API 接入的真实场景,逐步展示 DuckDB 在 HTTPS/API 数据接入方面的核心能力。
场景:电商平台销售数据 API 接入
假设我们有一个电商平台的销售数据 API,返回格式如下:
[
{
"order_id": "ORD-2026-0001",
"customer_id": "CUST-1001",
"product": "机械键盘",
"quantity": 2,
"unit_price": 399.00,
"total_amount": 798.00,
"order_date": "2026-06-10T14:30:00Z",
"status": "completed"
},
...
]
我们需要将这个 API 的数据拉取到 DuckDB 中进行分析和存储。
1. 加载 httpfs 扩展并读取远程 JSON
DuckDB 的 httpfs 扩展提供了 http_get() 函数和多种远程数据读取函数。首先加载扩展:
LOAD httpfs;
1.1 使用 read_json_auto 直接读取远程 URL
CREATE TABLE sales_data AS
SELECT * FROM read_json_auto(
'https://jsonplaceholder.typicode.com/posts',
columns={
'userId': 'BIGINT',
'id': 'BIGINT',
'title': 'VARCHAR',
'body': 'VARCHAR'
}
);
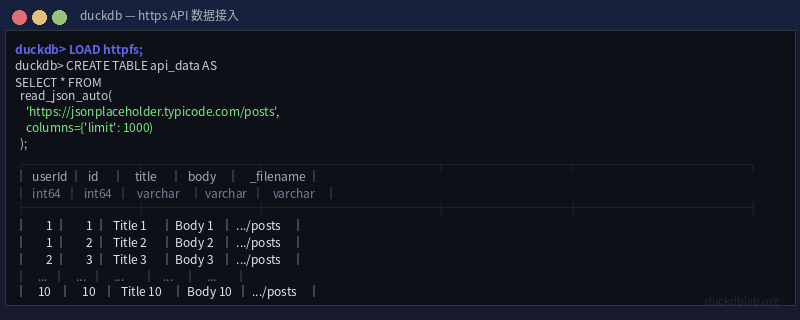
图:从远程 API 读取 JSON 数据的终端输出
read_json_auto 会自动检测 JSON 格式(数组或逐行 JSON),并根据数据推断列类型。我们也可以显式指定 columns 参数来强制类型转换。
1.2 使用 http_get 进行更灵活的数据获取
对于需要自定义 HTTP 头的 API(如 OAuth 认证),可以使用 http_get() 函数:
-- 设置认证头
SET http_user_agent = 'DuckDBDataPipeline/1.0';
-- 读取需要认证的 API
CREATE TABLE protected_data AS
SELECT * FROM read_json_auto(
http_get('https://api.example.com/v1/sales',
headers={'Authorization': 'Bearer YOUR_TOKEN'}
),
mode='raw',
union_name_by_column=true
);
http_get() 返回一个 BLOB 类型的响应体,可以配合 read_json_auto(..., mode='raw') 直接解析。
2. 读取远程 CSV 数据
除了 JSON,httpfs 扩展还支持直接读取远程 CSV 文件:
-- 读取远程 CSV 文件
CREATE TABLE remote_csv AS
SELECT * FROM read_csv_auto(
'https://raw.githubusercontent.com/plotly/datasets/master/equity_daily.csv',
auto_detect=true,
columns={
'Date': 'DATE',
'Open': 'DOUBLE',
'High': 'DOUBLE',
'Low': 'DOUBLE',
'Close': 'DOUBLE',
'Volume': 'BIGINT'
}
);
-- 查看数据概况
DESCRIBE remote_csv;
-- 统计最近 7 天的收盘价
SELECT Date, Close
FROM remote_csv
WHERE Date >= CURRENT_DATE - INTERVAL '7 days'
ORDER BY Date DESC;
read_csv_auto 的优势在于它会自动检测分隔符、推断列类型、处理缺失值。通过 columns 参数可以覆盖自动推断的结果。
3. 带认证和重试的 API 接入
生产环境中,API 通常需要认证并且可能出现临时故障。以下是一个完整的接入模板:
-- 配置 HTTP 全局设置
SET http_user_agent = 'DuckDBDataPipeline/1.0';
SET http_timeout = 30000; -- 5分钟超时
-- 使用 Bearer Token 认证
CREATE OR REPLACE VIEW api_sales_view AS
SELECT
order_id,
customer_id,
product,
quantity,
unit_price,
total_amount,
CAST(order_date AS TIMESTAMP) AS order_time,
status
FROM read_json_auto(
http_get(
'https://api.yourstore.com/v2/sales?limit=10000',
headers={
'Authorization': 'Bearer ' || {{env.DUCKDB_API_TOKEN}},
'Content-Type': 'application/json'
}
),
mode='raw',
union_name_by_column=true
);
-- 验证数据完整性
SELECT
COUNT(*) AS total_orders,
COUNT(DISTINCT customer_id) AS unique_customers,
SUM(total_amount) AS total_revenue,
AVG(total_amount) AS avg_order_value
FROM api_sales_view;
提示:在实际生产中,建议将 API Token 存储在环境变量中,通过
{{env.VAR_NAME}}语法在 SQL 中引用,避免硬编码敏感信息。
4. 增量拉取策略
全量拉取每次都会重新下载全部数据,效率低下。以下是几种常见的增量拉取策略:
4.1 基于时间戳的增量拉取
-- 记录上次拉取的最大时间戳
CREATE TABLE IF NOT EXISTS sync_state (
source VARCHAR PRIMARY KEY,
last_sync_timestamp TIMESTAMP
);
-- 首次初始化
INSERT INTO sync_state VALUES ('api_sales', '1970-01-01');
-- 增量拉取:只获取上次同步之后的新数据
CREATE OR REPLACE TEMP TABLE new_records AS
SELECT * FROM read_json_auto(
http_get(
'https://api.yourstore.com/v2/sales?updated_after=2026-06-11T00:00:00Z&limit=5000',
headers={'Authorization': 'Bearer ' || {{env.DUCKDB_API_TOKEN}}}
),
mode='raw'
);
-- 将新数据合并到主表(UPSERT 语义)
MERGE INTO sales_data target
USING new_records source
ON target.order_id = source.order_id
WHEN MATCHED THEN
UPDATE SET quantity = source.quantity,
total_amount = source.total_amount,
updated_at = CURRENT_TIMESTAMP
WHEN NOT MATCHED THEN
INSERT VALUES (source.*);
-- 更新同步状态
UPDATE sync_state
SET last_sync_timestamp = (SELECT MAX(order_date) FROM new_records)
WHERE source = 'api_sales';
4.2 基于游标的分页拉取
对于不支持 updated_after 参数的 API,可以使用游标分页:
-- 分页拉取所有数据
CREATE OR REPLACE TEMP TABLE all_pages AS
SELECT * FROM (
SELECT * FROM read_json_auto(
'https://api.yourstore.com/v2/sales?page=1&per_page=100',
union_name_by_column=true
)
UNION ALL
SELECT * FROM read_json_auto(
'https://api.yourstore.com/v2/sales?page=2&per_page=100',
union_name_by_column=true
)
UNION ALL
SELECT * FROM read_json_auto(
'https://api.yourstore.com/v2/sales?page=3&per_page=100',
union_name_by_column=true
)
);
-- 或者使用 Python 脚本动态构建分页查询
4.3 断点续拉
结合 sync_state 表和 OFFSET 实现断点续拉:
-- 从上次中断的位置继续拉取
CREATE OR REPLACE TEMP TABLE resumed_pull AS
SELECT * FROM read_json_auto(
http_get(
'https://api.yourstore.com/v2/sales?limit=1000&offset=5000',
headers={'Authorization': 'Bearer ' || {{env.DUCKDB_API_TOKEN}}}
),
mode='raw'
);
5. 性能优化建议
5.1 并行拉取
-- 设置线程数提升并发能力
SET threads = 4;
-- 并行读取多个 API 端点
CREATE TABLE combined_data AS
SELECT * FROM (
SELECT * FROM read_json_auto(
'https://api.store.com/v2/orders',
union_name_by_column=true
)
UNION ALL
SELECT * FROM read_json_auto(
'https://api.store.com/v2/products',
union_name_by_column=true
)
UNION ALL
SELECT * FROM read_json_auto(
'https://api.store.com/v2/customers',
union_name_by_column=true
)
);
5.2 缓存机制
对于不频繁变化的 API 数据,可以缓存到本地 Parquet 文件:
-- 首次拉取并保存为 Parquet
COPY (
SELECT * FROM read_json_auto(
'https://api.example.com/data',
union_name_by_column=true
)
) TO '/data/cache/api_data.parquet' (FORMAT PARQUET);
-- 后续直接从本地 Parquet 读取(速度提升 10-100 倍)
SELECT * FROM read_parquet('/data/cache/api_data.parquet');
5.3 数据过滤下推
在读取时就进行过滤,减少网络传输量:
-- 在 API 层就过滤(如果 API 支持)
CREATE TABLE filtered_data AS
SELECT * FROM read_json_auto(
'https://api.yourstore.com/v2/sales?status=completed&limit=10000',
union_name_by_column=true
);
-- 或者在 DuckDB 中过滤
CREATE TABLE completed_orders AS
SELECT * FROM api_sales_view
WHERE status = 'completed'
AND total_amount > 100;
6. 完整 ETL 管道示例
下面是一个完整的从 API 拉取、清洗到持久化的管道:
-- 1. 加载扩展
LOAD httpfs;
-- 2. 创建目标表
CREATE TABLE IF NOT EXISTS sales_pipeline (
order_id VARCHAR PRIMARY KEY,
customer_id VARCHAR,
product VARCHAR,
quantity INTEGER,
unit_price DOUBLE,
total_amount DOUBLE,
order_time TIMESTAMP,
status VARCHAR,
synced_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 3. 从 API 拉取并清洗
INSERT INTO sales_pipeline (
order_id, customer_id, product, quantity, unit_price,
total_amount, order_time, status
)
SELECT
order_id,
customer_id,
TRIM(product) AS product,
CAST(quantity AS INTEGER) AS quantity,
ROUND(unit_price, 2) AS unit_price,
ROUND(total_amount, 2) AS total_amount,
CAST(order_date AS TIMESTAMP) AS order_time,
LOWER(status) AS status
FROM read_json_auto(
http_get(
'https://api.yourstore.com/v2/sales?limit=10000',
headers={'Authorization': 'Bearer ' || {{env.DUCKDB_API_TOKEN}}}
),
mode='raw',
union_name_by_column=true
)
WHERE total_amount > 0;
-- 4. 导出为 Parquet 供 BI 工具使用
COPY sales_pipeline TO '/data/pipeline/sales_latest.parquet' (FORMAT PARQUET);
-- 5. 验证数据
SELECT
DATE(order_time) AS sale_date,
COUNT(*) AS orders,
SUM(total_amount) AS revenue,
ROUND(AVG(total_amount), 2) AS avg_order
FROM sales_pipeline
WHERE order_time >= CURRENT_DATE - INTERVAL '30 days'
GROUP BY DATE(order_time)
ORDER BY sale_date;
总结
通过 DuckDB 的 httpfs 扩展,我们可以:
- 零中间件:直接在 SQL 中读取远程 JSON/CSV,无需 Python 脚本中转
- 灵活认证:通过
http_get()支持 OAuth、Bearer Token 等认证方式 - 增量拉取:基于时间戳、游标或 OFFSET 实现高效增量同步
- 性能优化:并行拉取、本地缓存、过滤下推等多种优化手段
- 完整管道:从 API 拉取、清洗转换到 Parquet 持久化,全部在 DuckDB 内完成
这种方案特别适合中小规模的数据管道场景,大幅降低了数据工程的复杂度。
更多 DuckDB 实战技巧,请关注 Olap Studio(duckdblab.org)