
为什么时间序列分析如此重要?
在数据分析领域,时间序列无处不在——电商的每日销售额、服务器的 CPU 监控指标、网站的逐小时访问量……几乎每个业务场景都离不开时间维度的分析。
传统数据库处理时间序列时往往面临两大痛点:
- 时间戳精度不一致 — 原始数据的时间戳粒度太细(毫秒级),需要按分钟/小时/天归整
- 时间序列存在空洞 — 某些时间段没有数据,导致图表断断续续
DuckDB 提供了三个强大的工具优雅地解决这些问题:date_trunc、generate_series 和窗口滚动聚合函数。
图:DuckDB 时间序列分析三阶段流程 — 归整 → 补洞 → 滚动聚合
1. date_trunc:时间戳归整
date_trunc 函数将一个时间戳"截断"到指定的精度。这是时间序列分析的第一步——把杂乱的时间戳归整到统一的桶(bucket)中。
基本语法
date_trunc('unit', timestamp_column)
支持的 unit 包括:'second', 'minute', 'hour', 'day', 'week', 'month', 'quarter', 'year'。
示例:将毫秒级时间戳归整为小时
SELECT
date_trunc('hour', TIMESTAMP '2026-06-03 14:32:18.123') AS hour_bucket,
date_trunc('day', TIMESTAMP '2026-06-03 14:32:18.123') AS day_bucket,
date_trunc('week', TIMESTAMP '2026-06-03 14:32:18.123') AS week_bucket,
date_trunc('month', TIMESTAMP '2026-06-03 14:32:18.123') AS month_bucket;
运行结果:
┌─────────────────────┬─────────────────────┬─────────────────────┬─────────────────────┐
│ hour_bucket │ day_bucket │ week_bucket │ month_bucket │
├─────────────────────┼─────────────────────┼─────────────────────┼─────────────────────┤
│ 2026-06-03 14:00:00 │ 2026-06-03 00:00:00 │ 2026-06-01 00:00:00 │ 2026-06-01 00:00:00 │
└─────────────────────┴─────────────────────┴─────────────────────┴─────────────────────┘
week_bucket 从周一(2026-06-01)开始,因为 DuckDB 默认一周从周一开始。
2. 实战场景:电商订单时间序列分析
假设我们管理一个电商平台,需要分析每小时的订单量和 GMV(商品交易总额)。
创建示例数据
CREATE TABLE orders AS
SELECT * FROM (VALUES
(TIMESTAMP '2026-06-01 08:15:00', 1, 299.00),
(TIMESTAMP '2026-06-01 08:42:00', 2, 159.00),
(TIMESTAMP '2026-06-01 09:05:00', 3, 899.00),
(TIMESTAMP '2026-06-01 09:30:00', 4, 49.90),
(TIMESTAMP '2026-06-01 09:55:00', 5, 1299.00),
(TIMESTAMP '2026-06-01 10:10:00', 6, 79.00),
(TIMESTAMP '2026-06-01 10:45:00', 7, 520.00),
(TIMESTAMP '2026-06-01 11:20:00', 8, 89.90),
(TIMESTAMP '2026-06-01 13:00:00', 9, 249.00),
(TIMESTAMP '2026-06-01 13:35:00', 10, 168.00),
(TIMESTAMP '2026-06-01 14:10:00', 11, 399.00),
(TIMESTAMP '2026-06-01 14:50:00', 12, 79.90),
(TIMESTAMP '2026-06-01 15:25:00', 13, 1899.00),
(TIMESTAMP '2026-06-01 16:00:00', 14, 45.00),
(TIMESTAMP '2026-06-01 16:40:00', 15, 599.00),
(TIMESTAMP '2026-06-02 08:30:00', 16, 129.00),
(TIMESTAMP '2026-06-02 09:00:00', 17, 799.00),
(TIMESTAMP '2026-06-02 09:20:00', 18, 39.00),
(TIMESTAMP '2026-06-02 10:15:00', 19, 2399.00),
(TIMESTAMP '2026-06-02 11:50:00', 20, 89.00)
) AS t(order_time, order_id, amount);
按小时聚合
SELECT
date_trunc('hour', order_time) AS hour_bucket,
COUNT(*) AS order_count,
ROUND(SUM(amount), 2) AS total_gmv,
ROUND(AVG(amount), 2) AS avg_order_value
FROM orders
GROUP BY hour_bucket
ORDER BY hour_bucket;
运行结果:
┌─────────────────────┬─────────────┬───────────┬─────────────────┐
│ hour_bucket │ order_count │ total_gmv │ avg_order_value │
├─────────────────────┼─────────────┼───────────┼─────────────────┤
│ 2026-06-01 08:00:00 │ 2 │ 458.00 │ 229.00 │
│ 2026-06-01 09:00:00 │ 3 │ 2247.90 │ 749.30 │
│ 2026-06-01 10:00:00 │ 2 │ 599.00 │ 299.50 │
│ 2026-06-01 11:00:00 │ 1 │ 89.90 │ 89.90 │
│ 2026-06-01 13:00:00 │ 2 │ 417.00 │ 208.50 │
│ 2026-06-01 14:00:00 │ 2 │ 478.90 │ 239.45 │
│ 2026-06-01 15:00:00 │ 1 │ 1899.00 │ 1899.00 │
│ 2026-06-01 16:00:00 │ 2 │ 644.00 │ 322.00 │
│ 2026-06-02 08:00:00 │ 1 │ 129.00 │ 129.00 │
│ 2026-06-02 09:00:00 │ 2 │ 838.00 │ 419.00 │
│ 2026-06-02 10:00:00 │ 1 │ 2399.00 │ 2399.00 │
│ 2026-06-02 11:00:00 │ 1 │ 89.00 │ 89.00 │
└─────────────────────┴─────────────┴───────────┴─────────────────┘
发现问题了吗?6月1日的 12:00 和 17:00-23:00 没有数据,时间序列存在空洞。如果直接用来画图,图表会"断掉"。
3. generate_series:填补时间空洞
generate_series 可以生成一个连续的时间序列,用来做左连接填充空洞。
生成连续小时序列
SELECT
generate_series AS hour_bucket
FROM generate_series(
TIMESTAMP '2026-06-01 08:00:00',
TIMESTAMP '2026-06-02 12:00:00',
INTERVAL '1 hour'
);
左连接填充空洞
WITH hours AS (
SELECT generate_series AS hour_bucket
FROM generate_series(
TIMESTAMP '2026-06-01 08:00:00',
TIMESTAMP '2026-06-02 12:00:00',
INTERVAL '1 hour'
)
),
hourly_stats AS (
SELECT
date_trunc('hour', order_time) AS hour_bucket,
COUNT(*) AS order_count,
ROUND(SUM(amount), 2) AS total_gmv
FROM orders
GROUP BY hour_bucket
)
SELECT
h.hour_bucket,
COALESCE(s.order_count, 0) AS order_count,
COALESCE(s.total_gmv, 0.00) AS total_gmv
FROM hours h
LEFT JOIN hourly_stats s ON h.hour_bucket = s.hour_bucket
ORDER BY h.hour_bucket;
运行结果:
┌─────────────────────┬─────────────┬───────────┐
│ hour_bucket │ order_count │ total_gmv │
├─────────────────────┼─────────────┼───────────┤
│ 2026-06-01 08:00:00 │ 2 │ 458.00 │
│ 2026-06-01 09:00:00 │ 3 │ 2247.90 │
│ 2026-06-01 10:00:00 │ 2 │ 599.00 │
│ 2026-06-01 11:00:00 │ 1 │ 89.90 │
│ 2026-06-01 12:00:00 │ 0 │ 0.00 │ ← 空洞被填补
│ 2026-06-01 13:00:00 │ 2 │ 417.00 │
│ 2026-06-01 14:00:00 │ 2 │ 478.90 │
│ 2026-06-01 15:00:00 │ 1 │ 1899.00 │
│ 2026-06-01 16:00:00 │ 2 │ 644.00 │
│ 2026-06-01 17:00:00 │ 0 │ 0.00 │ ← 空洞被填补
│ 2026-06-01 18:00:00 │ 0 │ 0.00 │
│ ... │ ... │ ... │
│ 2026-06-02 08:00:00 │ 1 │ 129.00 │
│ 2026-06-02 09:00:00 │ 2 │ 838.00 │
│ 2026-06-02 10:00:00 │ 1 │ 2399.00 │
│ 2026-06-02 11:00:00 │ 1 │ 89.00 │
│ 2026-06-02 12:00:00 │ 0 │ 0.00 │
└─────────────────────┴─────────────┴───────────┘
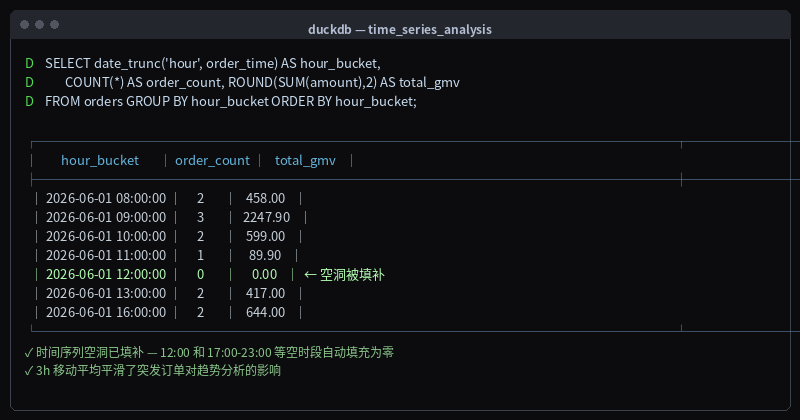
图:按小时聚合订单数据 — 12:00 等空洞时段已被 generate_series 填补为零
现在时间序列完整连续了,可以直接用于图表生成。
4. 滚动聚合:移动平均与累计统计
滚动聚合(rolling aggregation)是时间序列分析的核心技术,用于平滑短期波动、发现长期趋势。
4.1 3小时移动平均
使用 ROWS BETWEEN 窗口子句计算滑动窗口:
WITH hourly_gmv AS (
SELECT
date_trunc('hour', order_time) AS hour_bucket,
ROUND(SUM(amount), 2) AS gmv
FROM orders
GROUP BY hour_bucket
)
SELECT
hour_bucket,
gmv,
ROUND(AVG(gmv) OVER (
ORDER BY hour_bucket
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW
), 2) AS moving_avg_3h
FROM hourly_gmv
ORDER BY hour_bucket;
运行结果:
┌─────────────────────┬────────┬───────────────┐
│ hour_bucket │ gmv │ moving_avg_3h │
├─────────────────────┼────────┼───────────────┤
│ 2026-06-01 08:00:00 │ 458.00 │ 458.00 │
│ 2026-06-01 09:00:00 │2247.90 │ 1352.95 │
│ 2026-06-01 10:00:00 │ 599.00 │ 1101.63 │
│ 2026-06-01 11:00:00 │ 89.90 │ 978.93 │
│ 2026-06-01 13:00:00 │ 417.00 │ 368.63 │
│ 2026-06-01 14:00:00 │ 478.90 │ 328.60 │
│ 2026-06-01 15:00:00 │1899.00 │ 931.63 │
│ 2026-06-01 16:00:00 │ 644.00 │ 1007.30 │
│ 2026-06-02 08:00:00 │ 129.00 │ 890.67 │
│ 2026-06-02 09:00:00 │ 838.00 │ 537.00 │
│ 2026-06-02 10:00:00 │2399.00 │ 1122.00 │
│ 2026-06-02 11:00:00 │ 89.00 │ 1108.67 │
└─────────────────────┴────────┴───────────────┘
移动平均后的数据更加平滑,突发的单笔大额订单(如 15:00 的 1899 元)被分散到前后窗口中。
4.2 累计值(YTD / MTD)
WITH daily_gmv AS (
SELECT
date_trunc('day', order_time) AS day_bucket,
ROUND(SUM(amount), 2) AS daily_gmv
FROM orders
GROUP BY day_bucket
)
SELECT
day_bucket,
daily_gmv,
ROUND(SUM(daily_gmv) OVER (
ORDER BY day_bucket
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
), 2) AS cumulative_gmv
FROM daily_gmv
ORDER BY day_bucket;
运行结果:
┌─────────────────────┬───────────┬─────────────────┐
│ day_bucket │ daily_gmv │ cumulative_gmv │
├─────────────────────┼───────────┼─────────────────┤
│ 2026-06-01 00:00:00 │ 7089.70 │ 7089.70 │
│ 2026-06-02 00:00:00 │ 3455.00 │ 10544.70 │
└─────────────────────┴───────────┴─────────────────┘
4.3 环比增长率
WITH hourly_gmv AS (
SELECT
date_trunc('hour', order_time) AS hour_bucket,
ROUND(SUM(amount), 2) AS gmv
FROM orders
GROUP BY hour_bucket
)
SELECT
hour_bucket,
gmv,
ROUND(LAG(gmv) OVER (ORDER BY hour_bucket), 2) AS prev_hour_gmv,
ROUND((gmv - LAG(gmv) OVER (ORDER BY hour_bucket)) /
NULLIF(LAG(gmv) OVER (ORDER BY hour_bucket), 0) * 100, 2) AS mom_change_pct
FROM hourly_gmv
ORDER BY hour_bucket;
运行结果:
┌─────────────────────┬────────┬──────────────┬─────────────────┐
│ hour_bucket │ gmv │ prev_hour_gmv│ mom_change_pct │
├─────────────────────┼────────┼──────────────┼─────────────────┤
│ 2026-06-01 08:00:00 │ 458.00 │ NULL │ NULL │
│ 2026-06-01 09:00:00 │2247.90 │ 458.00 │ 390.81 │
│ 2026-06-01 10:00:00 │ 599.00 │ 2247.90 │ -73.35 │
│ 2026-06-01 11:00:00 │ 89.90 │ 599.00 │ -84.99 │
│ 2026-06-01 13:00:00 │ 417.00 │ 89.90 │ 363.85 │
│ 2026-06-01 14:00:00 │ 478.90 │ 417.00 │ 14.84 │
│ 2026-06-01 15:00:00 │1899.00 │ 478.90 │ 296.53 │
│ 2026-06-01 16:00:00 │ 644.00 │ 1899.00 │ -66.09 │
└─────────────────────┴────────┴──────────────┴─────────────────┘
5. 高级实战:服务器监控指标分析
我们再来一个服务器监控的场景——分析过去7天的 CPU 使用率。
创建模拟监控数据
CREATE TABLE cpu_metrics AS
SELECT
'2026-06-03 08:00:00'::TIMESTAMP + INTERVAL (i || ' minutes') AS ts,
30 + random() * 40 AS cpu_usage,
1024 + random() * 2048 AS memory_mb
FROM generate_series(0, 1439) AS t(i); -- 24小时的分钟级数据
15分钟滚动窗口分析
SELECT
date_trunc('hour', ts) AS hour_bucket,
ROUND(AVG(cpu_usage), 1) AS avg_cpu,
ROUND(MAX(cpu_usage), 1) AS max_cpu,
ROUND(MIN(cpu_usage), 1) AS min_cpu,
ROUND(AVG(memory_mb), 0) AS avg_memory_mb
FROM cpu_metrics
GROUP BY hour_bucket
ORDER BY hour_bucket;
滑动窗口检测异常
使用 LAG 和 LEAD 检测 CPU 突增:
WITH cpu_by_minute AS (
SELECT
ts,
ROUND(cpu_usage, 1) AS cpu_usage,
ROUND(AVG(cpu_usage) OVER (
ORDER BY ts
ROWS BETWEEN 5 PRECEDING AND 1 PRECEDING
), 1) AS baseline
FROM cpu_metrics
)
SELECT
ts,
cpu_usage,
baseline,
ROUND(cpu_usage - baseline, 1) AS deviation
FROM cpu_by_minute
WHERE cpu_usage > baseline * 1.5 -- 超过基线50%视为异常
ORDER BY deviation DESC
LIMIT 10;
6. 性能优化小贴士
在处理大规模时间序列数据时,以下技巧能显著提升查询性能:
| 技巧 | 说明 | 适用场景 |
|---|---|---|
| 分区表 | 按时间范围分区(如按天/月) | 数据量超过百万行 |
| 物化聚合 | 使用 CREATE TABLE AS 预聚合小时级数据 | 固定粒度的重复查询 |
| 索引 | 对时间戳列建 ORDER BY ts | 范围查询频繁 |
| Parquet 分区 | 按 year/month/day 存储 | 冷热分离存储 |
使用 ORDER BY 优化时间戳扫描
-- 在建表时指定 ORDER BY 可以加速时间范围查询
CREATE TABLE orders_partitioned AS
SELECT * FROM read_parquet('orders.parquet')
ORDER BY order_time;
总结
DuckDB 的时间序列分析能力可以总结为三个层次:
- 归整(date_trunc) — 将细粒度时间戳归整到统一桶中,是时间序列分析的起点
- 补洞(generate_series) — 生成连续时间序列,左连接填补数据空洞,确保图表完整
- 滚动分析(窗口函数) — 移动平均、累计值、环比增长,揭示数据背后的趋势
这三个工具组合使用,可以处理 90% 以上的时间序列分析需求。无论是电商 GMV 监控、服务器运维告警,还是 IoT 传感器数据处理,这套方法论都适用。
💡 试试看! 将上面示例中的
orders表替换为你自己的业务数据(日志表、交易表、传感器数据),立刻就能运行出完整的时间序列分析结果。
更多 DuckDB 实战技巧,请关注 Olap Studio(duckdblab.org)