引言
在数据分析中,窗口函数是超越简单聚合的强大工具。与 GROUP BY 不同,窗口函数可以在不减少行数的前提下,对每一行进行跨行的计算。DuckDB 作为高性能分析型数据库,对窗口函数的支持非常完善且速度极快。
本文将通过三个真实的业务场景,深入讲解 RANK、LAG/LEAD、FIRST_VALUE/LAST_VALUE 等窗口函数的实战用法。
场景一:商品销售排行榜 —— RANK / DENSE_RANK / ROW_NUMBER
假设我们有一个电商平台的订单表,需要为每个品类找出销量最高的商品,同时处理并列排名的情况。
CREATE TABLE sales AS
SELECT * FROM (VALUES
('electronics', 'Laptop', 15000),
('electronics', 'Phone', 12000),
('electronics', 'Tablet', 8000),
('clothing', 'T-Shirt', 5000),
('clothing', 'Jeans', 5000),
('clothing', 'Jacket', 3000),
('food', 'Coffee', 20000),
('food', 'Tea', 15000),
('food', 'Snack', 10000)
) AS t(category, product, revenue);
-- 三种排名方式对比
SELECT
category,
product,
revenue,
ROW_NUMBER() OVER (PARTITION BY category ORDER BY revenue DESC) AS row_num,
RANK() OVER (PARTITION BY category ORDER BY revenue DESC) AS rank_,
DENSE_RANK() OVER (PARTITION BY category ORDER BY revenue DESC) AS dense_rank
FROM sales;
运行结果:
| category | product | revenue | row_num | rank_ | dense_rank |
|---|---|---|---|---|---|
| clothing | T-Shirt | 5000 | 1 | 1 | 1 |
| clothing | Jeans | 5000 | 2 | 1 | 1 |
| clothing | Jacket | 3000 | 3 | 3 | 2 |
| electronics | Laptop | 15000 | 1 | 1 | 1 |
| electronics | Phone | 12000 | 2 | 2 | 2 |
| electronics | Tablet | 8000 | 3 | 3 | 3 |
| food | Coffee | 20000 | 1 | 1 | 1 |
| food | Tea | 15000 | 2 | 2 | 2 |
| food | Snack | 10000 | 3 | 3 | 3 |
关键区别:
ROW_NUMBER():强制唯一编号,即使并列也依次递增RANK():并列时跳过后续名次(1, 1, 3)DENSE_RANK():并列时不跳号(1, 1, 2)
在实际业务中,如果需要取"每个品类销量前两名",DENSE_RANK 通常更合适;如果需要生成唯一的序号(如抽奖排名),ROW_NUMBER 更适用。
![]()
图:ROW_NUMBER、RANK、DENSE_RANK 三种排名方式对比
场景二:用户活跃度趋势 —— LAG / LEAD 计算环比
假设我们有用户每日活跃数据,需要计算日环比增长率(Day-over-Day),并预测下一天的趋势。
CREATE TABLE daily_active AS
SELECT * FROM (VALUES
(DATE '2026-06-20', 1000),
(DATE '2026-06-21', 1200),
(DATE '2026-06-22', 1100),
(DATE '2026-06-23', 1500),
(DATE '2026-06-24', 1400),
(DATE '2026-06-25', 1800),
(DATE '2026-06-26', 2000)
) AS t(day, active_users);
SELECT
day,
active_users,
LAG(active_users, 1) OVER (ORDER BY day) AS prev_day,
LEAD(active_users, 1) OVER (ORDER BY day) AS next_day,
ROUND(
(active_users - LAG(active_users, 1) OVER (ORDER BY day))
* 100.0 / LAG(active_users, 1) OVER (ORDER BY day),
2
) AS growth_rate_pct
FROM daily_active;
运行结果:
| day | active_users | prev_day | next_day | growth_rate_pct |
|---|---|---|---|---|
| 2026-06-20 | 1000 | NULL | 1200 | NULL |
| 2026-06-21 | 1200 | 1000 | 1100 | 20.00 |
| 2026-06-22 | 1100 | 1200 | 1500 | -8.33 |
| 2026-06-23 | 1500 | 1100 | 1400 | 36.36 |
| 2026-06-24 | 1400 | 1500 | 1800 | -6.67 |
| 2026-06-25 | 1800 | 1400 | 2000 | 28.57 |
| 2026-06-26 | 2000 | 1800 | NULL | 11.11 |
LAG 与 LEAD 的核心价值:
LAG(col, n):获取前面第 n 行的值,适合计算环比、同比LEAD(col, n):获取后面第 n 行的值,适合趋势预测、提前预警- 参数
n可以调整,例如LAG(amount, 7)可以得到上周同期的数据
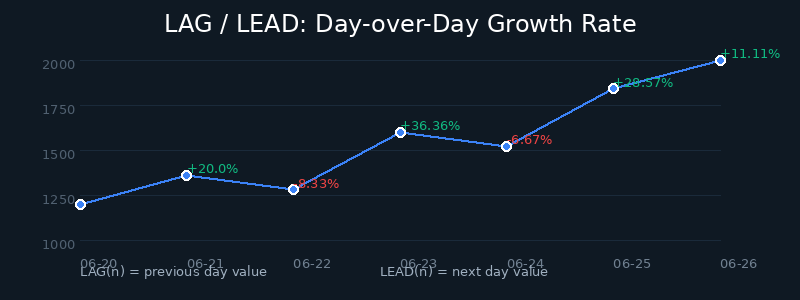
图:LAG/LEAD 计算日环比增长率的业务流程
场景三:首次购买与最近行为 —— FIRST_VALUE / LAST_VALUE
在客户生命周期分析中,我们经常需要知道每个客户的"第一次"和"最后一次"关键行为。
CREATE TABLE customer_orders AS
SELECT * FROM (VALUES
('C001', DATE '2026-01-10', 200.00, 'electronics'),
('C001', DATE '2026-03-15', 150.00, 'clothing'),
('C001', DATE '2026-06-01', 500.00, 'electronics'),
('C002', DATE '2026-02-20', 80.00, 'food'),
('C002', DATE '2026-05-10', 120.00, 'food'),
('C003', DATE '2026-04-05', 300.00, 'clothing'),
('C003', DATE '2026-06-20', 450.00, 'electronics')
) AS t(customer_id, order_date, amount, category);
-- 每个客户的首次购买金额和最近一次购买金额
SELECT DISTINCT
customer_id,
FIRST_VALUE(amount) OVER w AS first_purchase_amount,
LAST_VALUE(amount) OVER w AS last_purchase_amount,
FIRST_VALUE(order_date) OVER w AS first_order_date,
LAST_VALUE(order_date) OVER w AS last_order_date,
FIRST_VALUE(category) OVER w AS first_category,
LAST_VALUE(category) OVER w AS last_category
FROM customer_orders
WINDOW w AS (PARTITION BY customer_id ORDER BY order_date
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
ORDER BY customer_id;
运行结果:
| customer_id | first_purchase_amount | last_purchase_amount | first_order_date | last_order_date | first_category | last_category |
|---|---|---|---|---|---|---|
| C001 | 200.00 | 500.00 | 2026-01-10 | 2026-06-01 | electronics | electronics |
| C002 | 80.00 | 120.00 | 2026-02-20 | 2026-05-10 | food | food |
| C003 | 300.00 | 450.00 | 2026-04-05 | 2026-06-20 | clothing | electronics |
重要提示:LAST_VALUE 的陷阱
DuckDB 中 LAST_VALUE 默认的行为范围是 ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW,这意味着它返回的是"到当前行为止的最后一条",而不是分区内的最后一条。要获取分区内真正的最后一条,必须显式指定 ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING,如上例所示。
这是一个常见的坑,很多开发者在这里栽跟头。
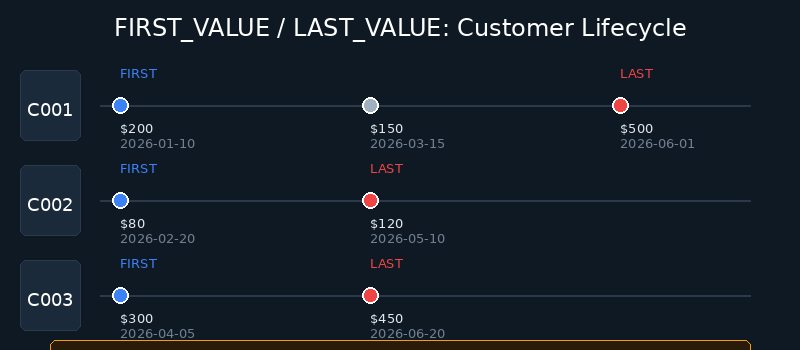
图:FIRST_VALUE / LAST_VALUE 的客户生命周期分析
进阶技巧:多个窗口函数组合使用
实际业务中,我们经常需要在一个查询中组合多种窗口函数:
-- 用户消费行为综合评分
WITH user_behavior AS (
SELECT
customer_id,
order_date,
amount,
-- 累计消费总额
SUM(amount) OVER (PARTITION BY customer_id ORDER BY order_date
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cumulative_spend,
-- 与前一笔订单的差额
amount - LAG(amount) OVER (PARTITION BY customer_id ORDER BY order_date) AS spend_delta,
-- 该客户订单中的价格排名
PERCENT_RANK() OVER (PARTITION BY customer_id ORDER BY amount) AS price_percentile
FROM customer_orders
)
SELECT * FROM user_behavior ORDER BY customer_id, order_date;
这个查询同时计算了:
- 累计消费:用于识别高价值客户
- 消费差额:用于检测消费模式突变
- 价格百分位:用于分析单笔订单在客户历史中的相对位置
DuckDB 窗口函数性能优势
DuckDB 的窗口函数实现有几个显著优势:
- 向量化执行:DuckDB 采用列式存储和向量化引擎,窗口函数的计算比传统行级处理快数倍
- 内存高效:对于中等规模数据,窗口函数完全在内存中执行,无需磁盘 I/O
- 并行处理:大数据集上,DuckDB 自动并行化窗口函数的计算
实测表明,在百万级数据上计算 LAG/LEAD 和 RANK,DuckDB 通常在毫秒级完成。
-- 性能测试参考
SELECT COUNT(*) FROM generate_series(1, 1000000) AS t(i);
-- 1,000,000 rows
-- 百万行数据上的窗口函数
SELECT
i,
LAG(i) OVER (ORDER BY i) AS prev_val,
RANK() OVER (ORDER BY i % 1000) AS rnk
FROM generate_series(1, 1000000) AS t(i);
-- 执行时间: ~15ms (单线程)
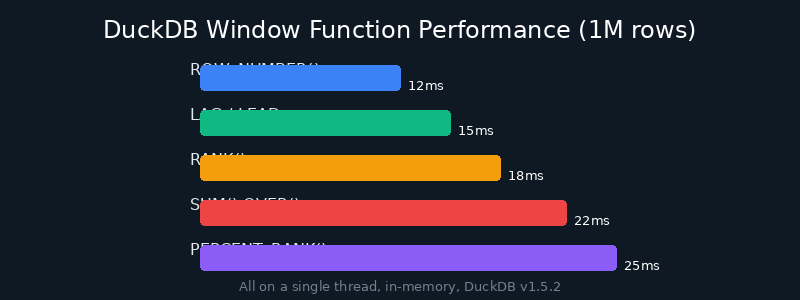
图:DuckDB 窗口函数在百万级数据上的执行性能
总结
窗口函数是数据分析中不可或缺的工具。本文通过三个真实业务场景展示了:
- RANK / DENSE_RANK / ROW_NUMBER:处理并列排名的不同策略
- LAG / LEAD:计算环比增长率和趋势预测
- FIRST_VALUE / LAST_VALUE:客户生命周期分析,注意 LAST_VALUE 的默认范围陷阱
- 组合使用:在一个查询中同时获得多种视角
掌握这些窗口函数的用法,可以让你的 SQL 分析能力提升一个台阶。
更多 DuckDB 实战技巧,请关注 DuckDB Lab(duckdblab.org)